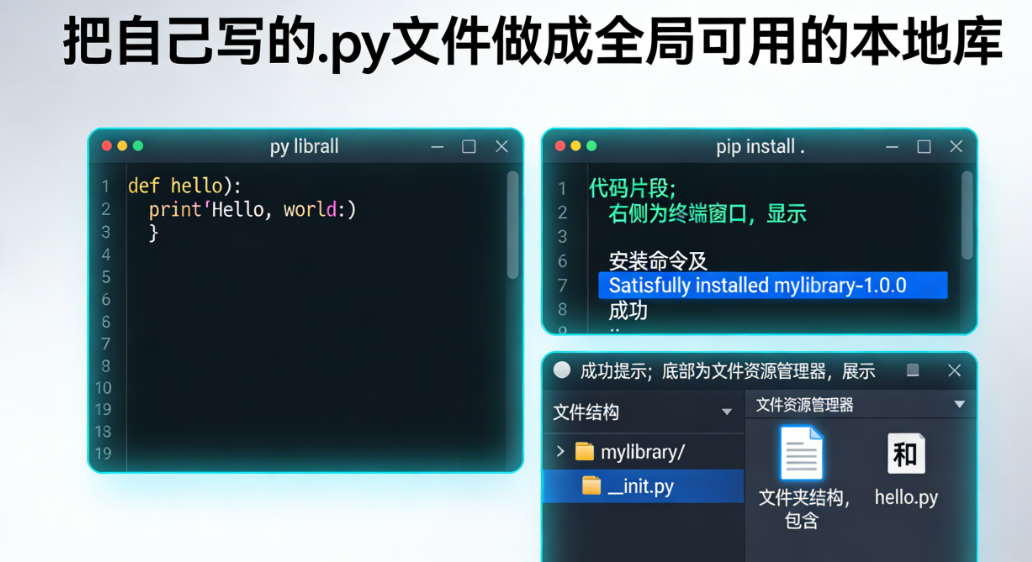
himawari8地球同步卫星影像瓦片下载

himawari8地球同步卫星影像瓦片下载
ytkzhimawari8地球同步卫星
地球静止轨道(或作“地球静止同步轨道”、“地球静止卫星轨道”、“克拉克轨道”)是特别指卫星或人造卫星垂直于地球赤道上方的正圆形地球同步轨道。地球静止轨道属于地球同步轨道的一种。
人造卫星与地面相对静止,固定在赤道上空。顺行的圆形轨道,距地面高度为35786千米,卫星运动速度为3.07千米/秒。一颗卫星可覆盖约40%的地球面积。气象卫星、通信卫星和广播卫星常采用这种轨道。另外我国的北斗卫星导航系统部分卫星也是使用该轨道。
2014年10月,日本首颗第三代气象卫星“向日葵”-8(Himawari-8)成功发射,定点在东经140°。
数据获取
himawari8近实时地把数据展示在互联网上,网站是https://himawari8.nict.go.jp/。
问题是我们能不能把数据下载在本地呢,答案是可以的。
下载himawari8的数据方法有多种,比如说注册账号通过FTP方式下载数据,数据的格式是NC格式。
我们这次下载数据选择第二种,下载它的瓦片数据,格式是png格式。
import requests
import datetime
import os
class himawari8():
def __init__(self, path):
self.path = 1
day = datetime.date.today()
self.path = path + '/' + str(day.year) + '-' + str(day.month) + '-' + str(day.day)
if os.path.exists(self.path ) == 0:
os.makedirs(self.path )
def download_img(self):
proxies = {'http': 'socks5h://127.0.0.1:7890',
'https': 'socks5h://127.0.0.1:7890'
}
headers = {
"User_Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
}
r'https://himawari8.nict.go.jp/img/D531106/20d/550/2022/07/04/235000_8_1.png'
'https://ncthmwrwbtst.cr.chiba-u.ac.jp/img/D531106/20d/550/2022/09/24/010000_0_1.png'
out = r'./2023/0226'
for i in range(0, 21):
for j in range(0, 21):
pngname = '030000_' + str(i) + '_' + str(j) + '.png'
out_pngname = os.path.join(self.path, pngname)
print(out_pngname)
# url = r'https://himawari8.nict.go.jp/img/D531106/20d/550/2022/07/04/' + pngname
url = r'https://ncthmwrwbtst.cr.chiba-u.ac.jp/img/D531106/20d/550/2023/02/27/'+ pngname
# r = requests.get(url, headers=headers, timeout=30, proxies=proxies)
r = requests.get(url, headers=headers, timeout=30)
with open(out_pngname, "wb") as code:
code.write(r.content)
if __name__ == '__main__':
path = r'xxxxx' # 路径
himawari8(path).download_img()
通过上面的爬虫程序,下载2023年2月的27日的一景地球遥感图片。一共有20*20=400张瓦片图片。
拼接
拼接方法是硬拼接,一张瓦片数据大小为550 550 3 。21行和21列,一共有441张。
使用Numpy创建一个为[x,y,z,k]的矩阵,其中x,y,z是行瓦片像素的大小,k代表瓦片的列。也就是[550*21,550,3,20]即 [11550,550,3,20]
下面是一张第5列、全部行的矩阵可视化展示。

先拼接行瓦片,得到20张行瓦片的矩阵,在这基础上再拼接列。最终得到一张像素为1155011550 3的地球图片,总像素为400207500个,约4亿像素,数据量为150Mb。
代码
这是总的代码,暂时没有继续优化的想法,现在仅供诸君参考:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : merge_img.py
import numpy as np
from PIL import Image
import datetime, time
import requests
import os
from osgeo import osr, gdal
import matplotlib.pyplot as plt
def get_file_name(file_dir, type1):
"""
搜索 后缀名为type的文件 不包括子目录的文件
#
"""
L = []
if type(type1) == str:
if len([type1]) == 1:
filelist = os.listdir(file_dir)
for file in filelist:
if os.path.splitext(file)[1] == type1:
L.append(os.path.join(file_dir, file))
if type(type1) != str:
if len(type1) > 1:
for i in range(len(type1)):
filelist = os.listdir(file_dir)
for file in filelist:
if os.path.splitext(file)[1] == type1[i]:
L.append(os.path.join(file_dir, file))
return L
def read_png_toarray(file, arr1=None):
try:
arr = np.array(Image.open(file))
if len(arr.shape) == 3:
x, y, z = arr.shape
if len(arr.shape) == 2:
x, y = arr.shape
arr = np.zeros(shape=(x, y, 3))
except:
x, y, z = arr1.shape
arr = np.zeros(shape=(x, y, 3))
return arr
def exec_string():
LOC = 'arr = np.vstack(('
for m in range(0, 20):
LOC = LOC + r'read_png_toarray(temp_png_list[' + str(m) + '],a1),'
LOC = LOC[:-1] + '))' \
'return arr'
exec(LOC)
a = 0
class himawari8():
def __init__(self, path):
self.path = 1
day = datetime.date.today()
self.path = path + '/' + str(day.year) + '-' + str(day.month) + '-' + str(day.day)
if os.path.exists(self.path ) == 0:
os.makedirs(self.path )
@property
def merge_img(self):
'''
exec无返回值,eval有返回值
@param path:
@param out:
@return:
'''
pnglist = get_file_name(self.path, '.png')
pnglist = doublesort(pnglist)
pnglist = [x[0] for x in pnglist]
temp_arr = np.zeros(shape=(550 * 21, 550, 3, 21))
j = 0
## First horizontal splicing, then vertical splicing
for i in range(0, 440, 21):
temp_png_list = pnglist[i:i + 21]
a1 = read_png_toarray(pnglist[0])
LOC = 'np.vstack(('
for m in range(0, 21):
LOC = LOC + r'read_png_toarray(temp_png_list[' + str(m) + '],a1),'
LOC = LOC[:-1] + '))'
arr = eval(LOC)
temp_arr[:, :, :, j] = arr
j += 1
if j == 13:
ass = 0
# arr = np.hstack((temp_arr[:, :, :, 0], temp_arr[:, :, :, 1], temp_arr[:, :, :, 2], temp_arr[:, :, :, 3],
# temp_arr[:, :, :, 4], temp_arr[:, :, :, 5], temp_arr[:, :, :, 6], temp_arr[:, :, :, 7])).astype(
# int)
string_run = 'np.hstack(('
for m in range(0, 21):
string_run = string_run + r'temp_arr[:,:,:,' + str(m) + '],'
string_run = string_run[:-1] + '))' + '.astype(int)'
arr = eval(string_run)
# save
img = Image.fromarray(np.uint8(arr))
out = os.path.dirname(pnglist[0])+'//result'
if os.path.exists(out)==0:
os.makedirs(out)
pngname = os.path.join(out, "all.png")
img.save(pngname) # himawari8Correct(pngname)
for i in range(21):
pngname = os.path.join(out, str(i)+".png")
img = Image.fromarray(np.uint8(temp_arr[:, :, :, i]))
img.save(pngname)
def download_img(self):
proxies = {'http': 'socks5h://127.0.0.1:7890',
'https': 'socks5h://127.0.0.1:7890'
}
headers = {
"User_Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
}
r'https://himawari8.nict.go.jp/img/D531106/20d/550/2022/07/04/235000_8_1.png'
'https://ncthmwrwbtst.cr.chiba-u.ac.jp/img/D531106/20d/550/2022/09/24/010000_0_1.png'
out = r'./2023/0226'
for i in range(0, 21):
for j in range(0, 21):
pngname = '030000_' + str(i) + '_' + str(j) + '.png'
out_pngname = os.path.join(self.path, pngname)
print(out_pngname)
# url = r'https://himawari8.nict.go.jp/img/D531106/20d/550/2022/07/04/' + pngname
url = r'https://ncthmwrwbtst.cr.chiba-u.ac.jp/img/D531106/20d/550/2023/02/27/'+ pngname
# r = requests.get(url, headers=headers, timeout=30, proxies=proxies)
r = requests.get(url, headers=headers, timeout=30)
with open(out_pngname, "wb") as code:
code.write(r.content)
def doublesort(flist):
# 双排序
'''
L = [(12, 12), (34, 13), (32, 15), (12, 24), (32, 64), (32, 11)]
L.sort(key=lambda x: (x[0], -x[1]))
'''
L = []
for i in range(len(flist)):
num1, num2, num3 = os.path.basename(flist[i]).split('_')
num3 = num3.split('.')[0]
L.append((flist[i], int(num2), int(num3)))
L.sort(key=lambda x: (x[1], x[2]))
return L
if __name__ == '__main__':
path = r''
himawari8(path).download_img()
himawari8(path).merge_img
a = 0
地理校正
以下代码是 为了测试,并不能直接使用,因为不够正确
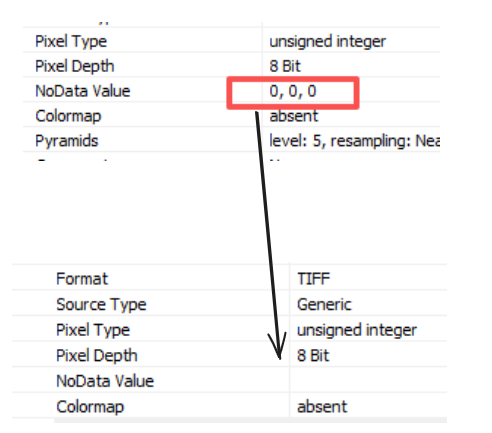
为了给png图片加上坐标系,这个过程也叫做地理校正(地理编码)
def himawari8Correct(file, res = 0.05):
# 几何校正
# 定义空间参考
ds = gdal.Open(file)
srs = osr.SpatialReference()
# 定义地球长半轴a=6378137.0m,地球短半轴b=6356752.3m,卫星星下点所在经度140.7,目标空间参考
srs.ImportFromProj4('+proj=geos +h=35785863 +a=6378137.0 +b=6356752.3 +lon_0=140.7 +no_defs')
ds.SetProjection(srs.ExportToWkt())
ds.SetGeoTransform([-5500000, 5500000, 0, 5500000, 0, -5500000])
outtif = os.path.join(os.path.dirname(file), 'result.tif')
if os.path.exists(outtif):
os.remove(outtif)
warpDs = gdal.Warp(outtif, ds, dstSRS='EPSG:4326', outputBounds=(60.0, -90.0, 222.0, 90.0), xRes=res, yRes=res)
### https://gis.stackexchange.com/questions/384514/georeferencing-himawari-8-images-with-rasterio
kwargs = {'format': 'VRT', 'outputSRS': '+proj=geos +h=35785863 +a=6378137.0 +b=6356752.3 +lon_0=140.7 +no_defs',
'outputBounds': [-5500000, 5500000, 5500000, -5500000]}
src_ds = gdal.Translate('/vsimem/test.vrt', file, **kwargs)
kwargs = {'format': 'GTiff', 'dstSRS': '+proj=latlong +ellps=WGS84 +pm=140.7', 'warpOptions': 'SOURCE_EXTRA=100'}
dst_ds = gdal.Warp('full_disk_ahi_true_color_20210116025000.tif', src_ds, **kwargs)
del warpDs0.05是默认参数:插值后空间分辨率为0.05度。
因为某些不为我知的原因,一下的边缘发生了严重的拉伸效果。
但是总体上还是可以的!

小结
该程序是作为练习爬虫、矩阵操作写的,其中的弊端是把下载影像的日期、时间写固定了,改进方向之一就是抽取日期和时间,包装成一个函数,这样方便调用。
其次这个程序缺少一个地理校正的步骤,也是在最后一步:把png赋予坐标,调用GDAL的接口就可以了,但是因为报错,我没有继续研究下去,估计是影像太大原因?虽然150M不大,但是地理校正会进行一个插值过程,插值完就很大了。 后面还是写好了,(#^.^#)
今天就到这里了,后面再看看QT、go、kotlin、pytorch的东西了,ヾ(◍°∇°◍)ノ゙
今天(2023年2月27日)的地球(东亚)挺好看的,下图这样子的: