目标检测的YOLOv3模型搭建的过程
目标检测的YOLOv3模型搭建的过程
ytkzYOLO v3是一种流行的用于实时物体检测的卷积神经网络(CNN) ,由Redmon等人于 2018 年发布。距今已有6年了,现在目标检测yolo算法已经发展到了yolov10,但是对于我这个深度学习新手来说,是有必要去深入学习一下经典的yolov3。
我第一次看到yolo这个词是在unknowncheats论坛,看到一个国外老哥用yolov3制作守望先锋的锁头挂,他提供了测试视频,视频里他的士兵76确实很猛。据他说yolov3的目标检测速度快,当时我也在玩守望先锋,所以记忆比较深刻。当时我的python玩得不六,当时只能默默膜拜一下大佬的操作。
我们还是来看看yolov3的整体架构吧。
You Only Look Once
YOLO代表“ You Only Look Once ”,翻译为中文就是你只需要看一次。在yolo之前也有一些目标检测模型,它们一般是通过滑块批量地检测是否存在目标。
实际上,YOLO v3是同类中第一个端到端网络。yolov3属于cnn模型,yolov3的主干网络使用了特征金字塔网络(Feature Pyramid Network, FPN)和Darknet-53
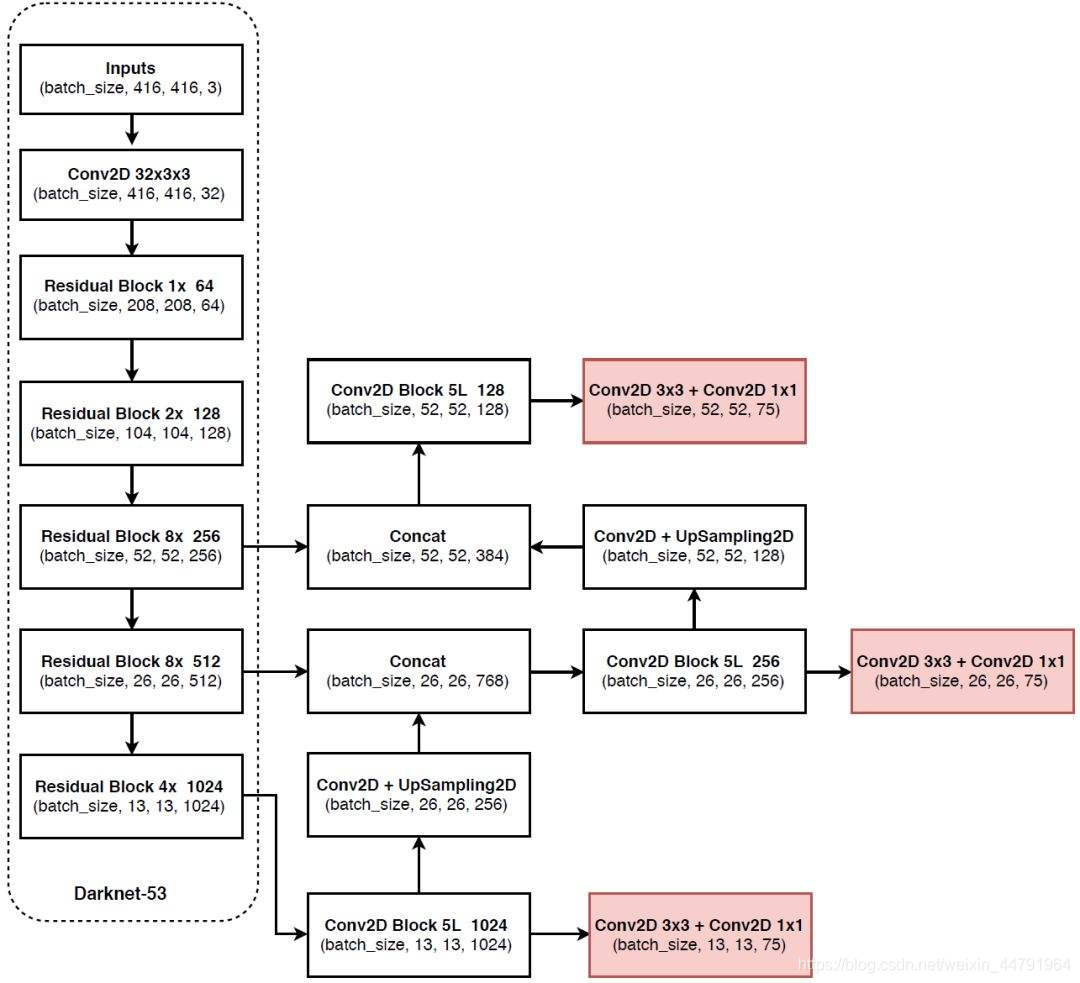
今天的学习目标就是弄清楚yolov3的主干网络是什么,以输入416 × 416 × 3尺寸的图像为例,在yolov3的主干网络中特征提取过程如下图所示。
虚线内是Darknet-53,虚线外是金字塔网络FPN。
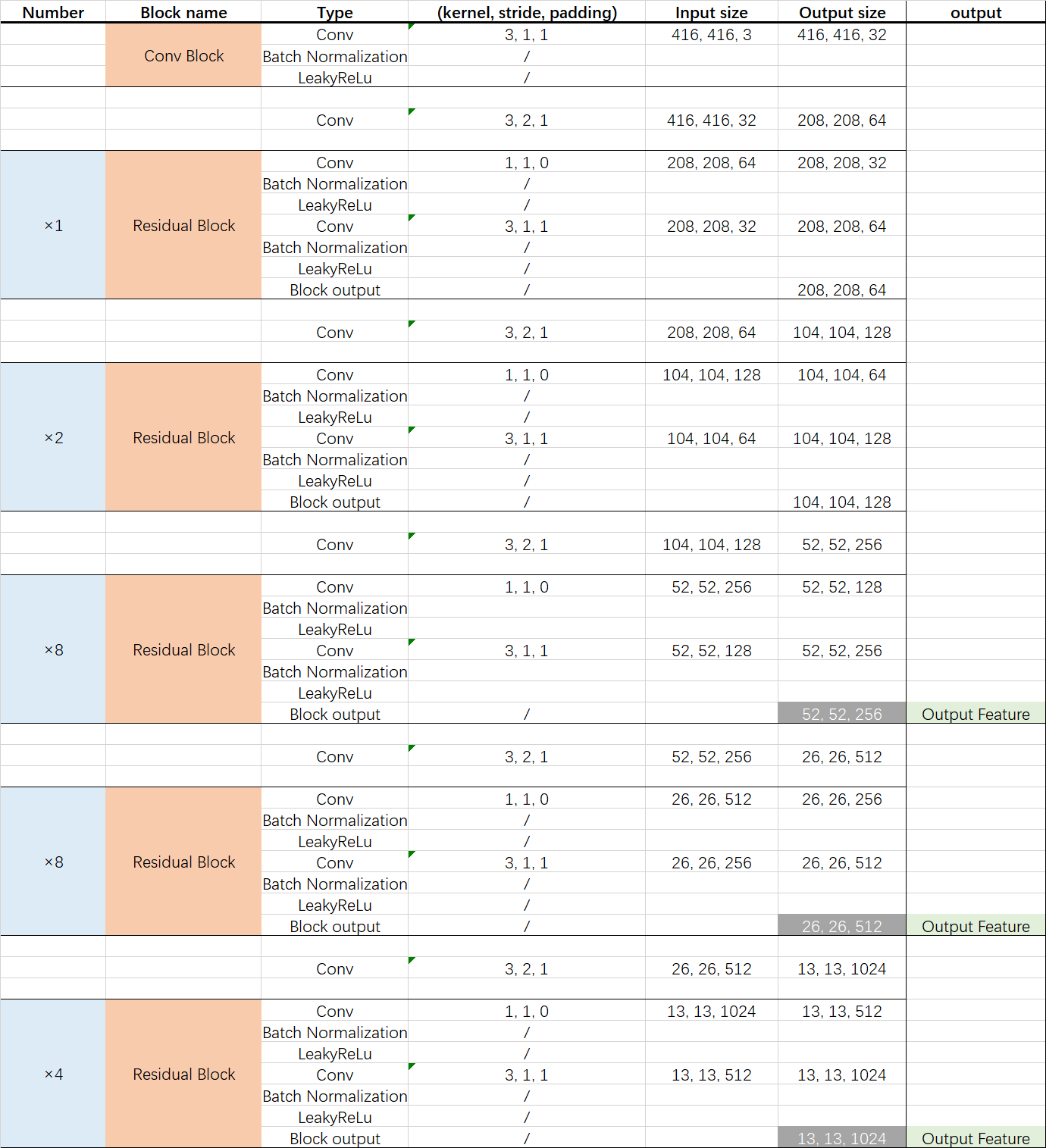
网上、论文说Darknet-53之所以叫Darknet-53,是因为有53个卷积。但是,我数了很多次它只有52个卷积。
Darknet-53的代码实现
代码自己写的,花了很多时间,在这个过程中一边参考上面的yolov3的网络一边调试。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2024/9/4 下午20:17
# @File : yolov3model.py
import torch
import torch.nn as nn
# Basic convolution block
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.leaky_relu = nn.LeakyReLU(0.1)
def forward(self, x):
return self.leaky_relu(self.bn(self.conv(x)))
# Residual block used in Darknet-53
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, in_channels // 2, kernel_size=1, stride=1, padding=0)
self.conv2 = ConvBlock(in_channels // 2, in_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
return x + self.conv2(self.conv1(x))
# Darknet-53 backbone network
class Darknet53(nn.Module):
def __init__(self):
super(Darknet53, self).__init__()
self.conv1 = ConvBlock(3, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = ConvBlock(32, 64, kernel_size=3, stride=2, padding=1)
self.residual1 = nn.Sequential(*[ResidualBlock(64) for _ in range(1)])
self.conv3 = ConvBlock(64, 128, kernel_size=3, stride=2, padding=1)
self.residual2 = nn.Sequential(*[ResidualBlock(128) for _ in range(2)])
self.conv4 = ConvBlock(128, 256, kernel_size=3, stride=2, padding=1)
self.residual3 = nn.Sequential(*[ResidualBlock(256) for _ in range(8)])
self.conv5 = ConvBlock(256, 512, kernel_size=3, stride=2, padding=1)
self.residual4 = nn.Sequential(*[ResidualBlock(512) for _ in range(8)])
self.conv6 = ConvBlock(512, 1024, kernel_size=3, stride=2, padding=1)
self.residual5 = nn.Sequential(*[ResidualBlock(1024) for _ in range(4)])
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.residual1(x)
out1 = x
x = self.conv3(x)
x = self.residual2(x)
out2 = x
x = self.conv4(x)
x = self.residual3(x)
out3 = x
x = self.conv5(x)
x = self.residual4(x)
out4 = x
x = self.conv6(x)
x = self.residual5(x)
out5 = x
return out3, out4, out5 # 输出三个不同尺度的特征图
# YOLO detection head
class YOLOHead(nn.Module):
def __init__(self, in_channels, out_channels):
super(YOLOHead, self).__init__()
self.head = nn.Sequential(
ConvBlock(in_channels, out_channels, kernel_size=1, stride=1, padding=0),
ConvBlock(out_channels,in_channels, kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, out_channels, kernel_size=1, stride=1, padding=0),
ConvBlock(out_channels,in_channels, kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, out_channels, kernel_size=1, stride=1, padding=0),
)
def forward(self, x):
return self.head(x)
# YOLOv3 with feature fusion
class YOLOv3(nn.Module):
def __init__(self, num_classes=80, anchors_num=3):
super(YOLOv3, self).__init__()
self.backbone = Darknet53()
# 此时是13x13x512
self.yolo_head1 = YOLOHead(1024,512) # Large scale detection
self.final_out_1 = nn.Sequential(
nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=1),
nn.Conv2d(1024, anchors_num*(num_classes+5), kernel_size=1, stride=1, padding=0),
)
self.last_layer1_conv = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.yolo_head2 = YOLOHead(768, 256) # midum scale detection
self.final_out_2 = nn.Sequential(
nn.Conv2d(256, 100, kernel_size=3, stride=1, padding=1),
nn.Conv2d(100, anchors_num * (num_classes + 5), kernel_size=1, stride=1, padding=0),
)
self.last_layer2_conv = nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.yolo_head3 = YOLOHead(384, 128) # samll scale detection
self.final_out_3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(256, anchors_num * (num_classes + 5), kernel_size=1, stride=1, padding=0),
)
def forward(self, x):
out3, out4, out5 = self.backbone(x)
head1 = self.yolo_head1(out5)
y1 = self.final_out_1(head1)
fusion1 = self.last_layer1_conv(head1)
fusion1 = self.last_layer1_upsample(fusion1)
fusion1 = torch.cat([fusion1, out4], dim=1)
head2 = self.yolo_head2(fusion1)
y2 = self.final_out_2(head2)
fusion2 = self.last_layer2_conv(head2)
fusion2 = self.last_layer2_upsample(fusion2)
fusion2 = torch.cat([fusion2, out3], dim=1)
head3 = self.yolo_head3(fusion2)
y3 = self.final_out_3(head3)
return y1, y2, y3 # 返回三个不同尺度的输出
if __name__ == '__main__':
# Initialize model
model = YOLOv3(num_classes=80)
# Print model architecture
print(model)
# 设定输入图像的尺寸
input_size = (1, 3, 416, 416) # batch_size, channels, height, width
# 创建一个随机的输入张量
input_tensor = torch.randn(*input_size)
# 初始化YOLOv3模型
model = YOLOv3(num_classes=20)
# 将输入张量传递给模型
with torch.no_grad(): # 关闭梯度计算,因为这只是测试
outputs = model(input_tensor)
# 输出每个尺度的检测结果
for i, output in enumerate(outputs):
print(f"Output {i+1} shape: {output.shape}")网络搭建起来,其余部分就差读取数据集、定义损失函数。等模型训练好了,还要写一个预测脚本。
题外话
yolo、yolov2、yolov3是同一个作者写的,其他的版本是其他人魔改的版本。那后续者为什么也叫yolov呢?可能是因为yolo的名气大。相当于前几年的盗版小说网站都叫笔趣阁一样。
yolo的原作者Joseph Redmon在2020年初由于自己的开源算法用于军事和隐私问题,宣布退出CV领域。
参考: