编程 | Landsat9影像转真彩色RGBA缩略图

编程 | Landsat9影像转真彩色RGBA缩略图
ytkzLandsat 9
从USGS下载Landsat9影像,Landsat9影像和国产影像不一样的地方在于:
1.Landsat9影像已做好了几何校正,无rpc文件。
2.Landsat9影像以单波段的形式,将每个波段保存为单独的文件。
Landsat9 的真彩色RGBA
众所周知,Landsat9的第2波段是蓝色,Blue,简写B
Landsat9的第3波段是绿色,Green,简写G
Landsat9的第4波段是红色,Red,简写R
接下来,要写一个函数,实现这个功能:
输入Landsat9解压后的文件夹,得到Landsat9的第2、3、4波段的文件名
这个函数的作用是,有利于自动化,每景影像的名字是唯一的,如果每次都要自己手动指定Landsat9的第2、3、4波段的文件名是费时费力的。
注意分析Landsat9的tif名字的格式,提炼出共同的命名规则。
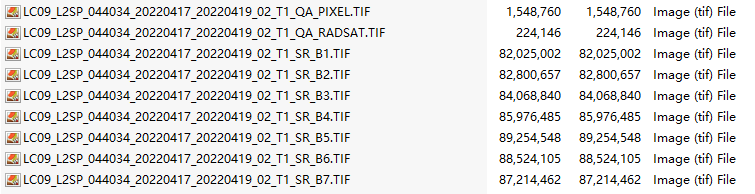
LC09_L2SR_018113_20230209_20230310_02_T2_SR_B1.TIF 的特点是
B1代表band 1 ,第一波段。
该文件的后缀是大写字母 TIF。
根据这两点可以自动获取第2、3、4波段的名字。
细看以下代码:
class landsat9_to_webp:
def __init__(self, path):
self.path = path
def get_tif_file(self, file_dir, type = '.TIF'):
# 获取TIF文件
"""
搜索 后缀名为type的文件 不包括子目录的文件
"""
L = []
if type(type) == str:
if len([type]) == 1:
filelist = os.listdir(file_dir)
for file in filelist:
if os.path.splitext(file)[1] == type:
L.append(os.path.join(file_dir, file))
if type(type) != str:
if len(type) > 1:
for i in range(len(type)):
filelist = os.listdir(file_dir)
for file in filelist:
if os.path.splitext(file)[1] == type[i]:
L.append(os.path.join(file_dir, file))
return L我们先写一个类,这个类叫做landsat9_to_webp,我们常常用self代指这个类。landsat9_to_webp这个类的输入是lansat9文件夹路径,所以这个类的其中一个属性是输入路径。
这个类 有一个类方法,叫做 get_tif_file,这个也是landsat9_to_webp是属性。get_tif_file方法实现查找 指定文件夹下 后缀为TIF的文件,若文件存在则返回符合条件的文件名字的列表。
下面是 示例
path = r'X:\LC09_L2SP_121038_20220616_20230411_02_T1'
filelist = landsat9_to_webp(path).get_tif_file()我们把filelist循环打印出来,瞧瞧它到底长啥样。
import os
for file in filelist:
print(os.path.basename(file))控制台打印一下信息:
LC09_L2SP_121038_20220616_20230411_02_T1_QA_PIXEL.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_QA_RADSAT.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B1.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B2.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B3.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B4.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B5.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B6.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B7.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_QA_AEROSOL.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_ATRAN.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_B10.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_CDIST.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_DRAD.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_EMIS.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_EMSD.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_QA.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_TRAD.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_ST_URAD.TIF
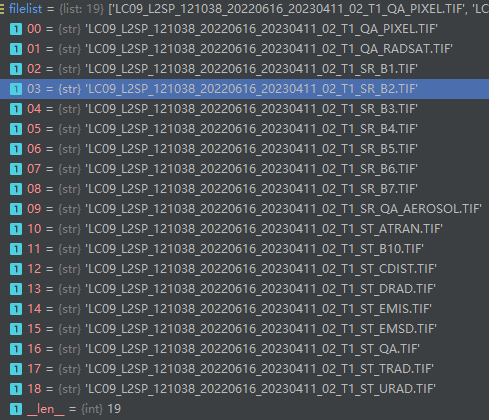
显然,filelist是一个长度为19的列表,下图是在pycharm的截图
这时候,我们已经成功一半了。
下一步,是对这个列表进行数据清洗,目的是稳定地找到我们所需要的波段。
有基础的朋友会注意到,filelist的第4个元素、第5个元素、第6个元素就是我们所需要的B2、B3、B4波段。为什么还有做数据清理呢? 理由有以下:
不能肯定、不能确定每次获得的filelist的第4个元素、第5个元素、第6个元素就是我们所需要的B2、B3、B4波段。
比如,我用sentinel-2举例,sentinel-2 L1C数据和sentinel-2 L2A数据就存在文件结构差异,所以不能保证每次都是filelist[3]、filelist[4]、filelist[5] 就是我们所要的文件名字。
这里我们再写几行代码,确保下一步读取是文件,就是Landsat9的第2、3、4波段。
笨方法就是循环filelist列表,加上一个if语句,如果当前元素存在B2.TIF,则该元素就是 第2波段的名字。
我们再写一个 类方法,
再次,整合代码,如下:
class landsat9_to_webp:
def __init__(self, path):
self.path = path
def get_tif_file(self, filetype = '.TIF'):
# 获取TIF文件
"""
搜索 后缀名为type的文件 不包括子目录的文件
"""
L = []
if type(filetype) == str:
if len([filetype]) == 1:
filelist = os.listdir(self.path)
for file in filelist:
if os.path.splitext(file)[1] == filetype:
L.append(os.path.join(self.path, file))
if type(filetype) != str:
if len(filetype) > 1:
for i in range(len(filetype)):
filelist = os.listdir(self.path)
for file in filelist:
if os.path.splitext(file)[1] == type[i]:
L.append(os.path.join(self.path, file))
return L
def finded_2_3_4_band(self):
filelist = self.get_tif_file()
for file in filelist:
if 'B2.TIF' in file:
B2file = file
elif 'B3.TIF' in file:
B3file = file
elif 'B4.TIF' in file:
B4file = file
return [B2file, B3file, B4file]ok,调用这个类,这个类的方法有两个finded_2_3_4_band,get_tif_file
我们解析一下目前这个类的运行逻辑。
首先实例化这个类。
其次调用finded_2_3_4_band方法。
然后finded_2_3_4_band方法 ,会调用get_tif_file这个方法。
最后返回一个列表,这个列表包含了B2file, B3file, B4file三个元素。
path = r'X:\LC09_L2SP_121038_20220616_20230411_02_T1'
filelist = landsat9_to_webp(path).finded_2_3_4_band()
我们把filelist循环打印出来,瞧瞧它到底长啥样。
import os
for file in filelist:
print(os.path.basename(file))控制台打印一下信息:
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B2.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B3.TIF
LC09_L2SP_121038_20220616_20230411_02_T1_SR_B4.TIF完成一个功能了,通过文件夹获取Landsat9影像的第2、3、4波段的文件名
GDAL 读取tif
得到对应的文件名后,我们通过gdal把tif读取到内存里。
利用numpy创建一个为【X,Y,4】的矩阵。
将对应的RGB波段数据放到矩阵的第1维到第3维。
第4维放置 透明度。
最后,返回矩阵。
ds1 = gdal.Open(self.bluefile)
blue = ds1.ReadAsArray()
ds2 = gdal.Open(self.greenfile)
green = ds2.ReadAsArray()
ds3 = gdal.Open(self.redfile)
red = ds3.ReadAsArray()
x, y = blue.shape
new_arr = np.zeros(shape=[x, y, 4]) # 构造一个新的零矩阵
new_arr[:, :, 0] = linear_stretch(blue) # 数据拉伸
new_arr[:, :, 1] = linear_stretch(green)
new_arr[:, :, 2] = linear_stretch(red)
new_arr[:, :, 3][blue != 0] = 255 # 透明度.
我们在生成new_arr的时候,使用了
new_arr = np.zeros(shape=[x, y, 4]) # 构造一个新的零矩阵所以new_arr是一个长为x,宽为y,维度(深度)为4的矩阵,并且全部数值均为0。
透明度解析
python的索引是从0开始计数,
所以new_arr[:, :, 3]代表new_arr的第4维。
new_arr[:, :, 3][blue != 0] = 255 # 透明度.以上代码的意思是,标记所有blue矩阵中不等于0像素的位置,暂时赋予给new_arr的第4维,将这些位置上的数值改写为255。
简单来说,就是将蓝色波段中存在不为零的像素的透明度设置为 不透明,将蓝色波段中存在为零的像素的透明度设置为透明。
数据拉伸
为什么要做数据拉伸,我曾经写过一篇公众号进行解释。
这里简单说一下,因为Landsat9的数据类型是16bit,而计算机屏幕显示的范围是8bit,16bit转为8bit这个过程叫做数据拉伸。
线性拉伸,也是等比例拉伸,具体代码如下:
def linear_stretch(data, num=1):
'''
@param data: 待拉伸的矩阵
@param num: 拉伸系数,一般为1-5
@return: 拉伸后的矩阵
'''
x, y = np.shape(data)
data_8bit = data
data_8bit[data_8bit == -9999] = 0
# 把数据中的nan转为某个具体数值,例如
# data_8bit[np.isnan(data_8bit)] = 0
d2 = np.percentile(data_8bit, num)
u98 = np.percentile(data_8bit, 100 - num)
maxout = 255
minout = 0
data_8bit_new = minout + ((data_8bit - d2) / (u98 - d2)) * (maxout - minout)
data_8bit_new[data_8bit_new < minout] = minout
data_8bit_new[data_8bit_new > maxout] = maxout
data_8bit_new = data_8bit_new.astype(np.int32)
return data_8bit_new整合代码
项目地址是在:
https://github.com/ytkz11/landsat9_to_rgba
如果对你有帮助,点赞是我最大的创作动力,