【深度学习】从LeNet学神经网络搭建
【深度学习】从LeNet学神经网络搭建
ytkzLeNet是最早的卷积神经网络之一,其被提出用于识别手写数字和机器印刷字符。 1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。
现代的神经网络模型,包括深度学习模型,其底层的数学原理与LeNet等早期的神经网络模型是一致的。这些基础原理包括卷积、池化、激活函数、反向传播等。
PyTorch等深度学习框架对这些底层库进行了高级的封装,使得我们可以通过调用API来快速、简便地实现这些操作,而不需要关心底层的具体实现。这极大地提高了我们开发和实现深度学习模型的效率。
然而,尽管我们可以通过调用API来实现各种操作,但是我们仍然需要理解和掌握如何搭建网络模型的结构。这包括如何选择合适的网络结构,如何设置各层的参数,如何设计损失函数和优化策略等。这些都是实现一个有效的神经网络模型所必需的知识和技能。
LeNet结构
LeNet的基本结构包括两个卷积层,两个池化层(下采样层),以及两个全连接层。它的结构可以简单地表示为:输入 - 卷积 - 池化 - 卷积 - 池化 - 全连接 - 全连接 - 输出。
LeNet的设计哲学在今天的深度神经网络中仍然被广泛应用。例如,卷积层用于提取图像的局部特征,池化层用于降低特征的空间大小以及控制过拟合,全连接层则用于对特征进行高级别的推理。
尺寸计算公式
尺寸计算公式,是用来计算卷积神经网络中卷积层输出特征图的尺寸的。具体来说,这个公式对应于一个卷积操作,这个通用公式,经常用得到。
- 输出特征图的高度:
CH_{out} = K
输出通道 = 卷积/池化核数量
H{in} 和 W{in}:输入特征图的高度和宽度。
P:填充(Padding)的大小。填充是在输入特征图的周围添加额外的“像素”或“单元”,
H{ker} 和 W{ker}:卷积核(也称为过滤器)的高度和宽度。
S:步长(Stride),即卷积核在输入特征图上移动的步数。
K:卷积核的数量,也是输出特征图的深度。
输出通道 = 卷积/池化核数量
$$
输入数据是灰度图,宽高均为32,通道数为1(这里省去不写),所以大小为32x32
32x32的数据,经过一个大小为6x5x5的卷积核,无填充,步长为1,下一个特征图大小计算过程如下:
输出宽度为 (32+2x0-5)/1+1=27+1=28
输出高度为 (32+2x0-5)/1+1=27+1=28,参数一样,下面不写输出高度的推导过程。
输出深度为6
此时,特征图大小为6x28x28。将此特征图进行下一步。
6x28x28的数据,经过一个大小为6x2x2的池化核,无填充,步长为2,下一个特征图大小计算过程如下:
输出宽度为 (28+2x0-2)/2+1=13+1=14
输出深度为6
此时,特征图大小为6x14x14。将此特征图进行下一步。
6x14x14的数据,经过一个大小为16x5x5的卷积核,无填充,步长为1,下一个特征图大小计算过程如下:
输出宽度为 (14+2x0-5)/1+1=9.5+1=10.5, 往下取整,为10
输出深度为16
此时,特征图大小为16x10x10。将此特征图进行下一步。
16x10x10的数据,经过一个大小为16x2x2的卷积核,无填充,步长为2,下一个特征图大小计算过程如下:
输出宽度为 (10+2x0-2)/2+1=4.5+1=5.5, 往下取整,为5
输出深度为16
此时,特征图大小为16x5x5。将此特征图进行下一步。
经过第一个全连接层,其输入特征数量为16x5x5=400,输出特征数量为120,得到120的特征图,即长度为120的向量。
经过第二个全连接层,其输入特征数量为120,输出特征数量为84,得到84的特征图
输出层,其输入特征数量为84,输出特征数量为10,得到长度为10的特征图
LeNet 实战
90行代码,实现LeNet模型对图像分类。
训练模型代码如下:
import torch
from torch import nn
import sys
import torchvision
import torchvision.transforms as transforms
import time
def load_data_fashion_mnist(mnist_train, mnist_test, batch_size):
if sys.platform.startswith('win'):
num_workers = 0
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16 * 4 * 4, 120),
# 这里是16x4x4的原因是,数据源大小为28x28,而不是32x32
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
n += y.shape[0]
return acc_sum / n
def train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
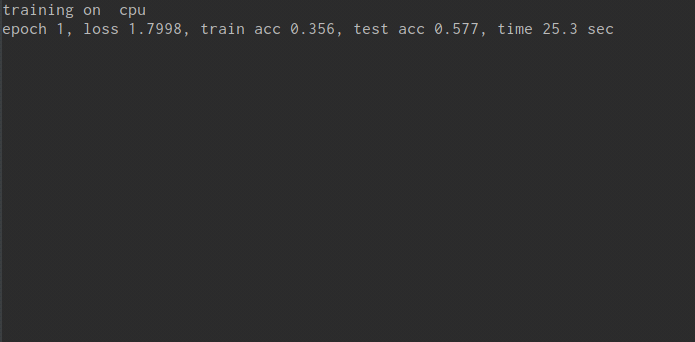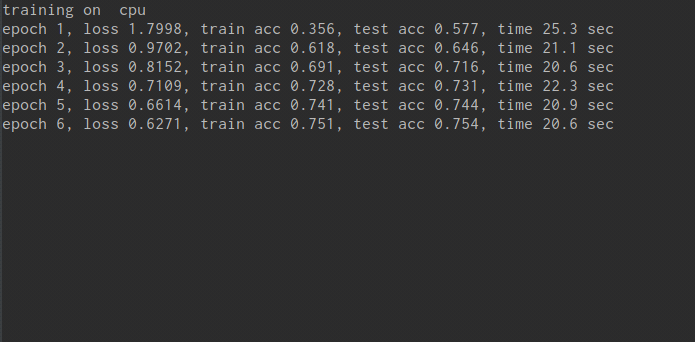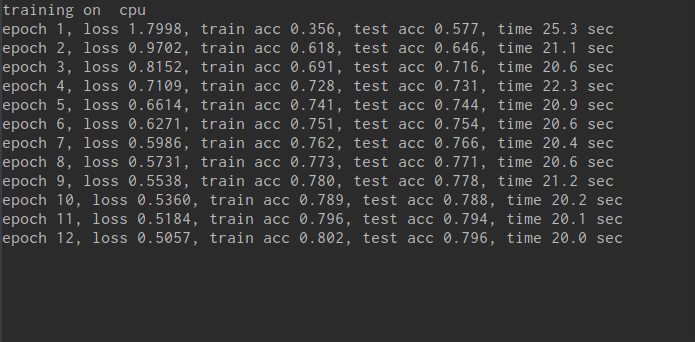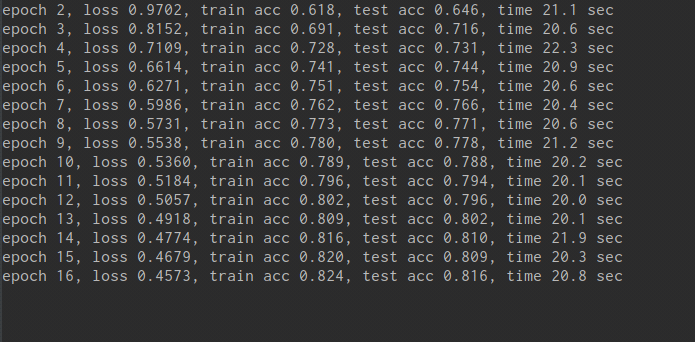
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if __name__ == '__main__':
net = LeNet()
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=False, download=True,
transform=transforms.ToTensor())
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(mnist_train, mnist_test, batch_size)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
lr, num_epochs = 0.001, 50
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)这段代码实现了一个完整的机器学习过程,包括数据加载、模型定义、模型训练、模型评估和模型保存。具体步骤如下:
- 数据加载:使用
torchvision.datasets.FashionMNIST加载FashionMNIST数据集,并使用transforms.ToTensor()将图片转换为张量。然后使用torch.utils.data.DataLoader创建数据加载器,用于在训练过程中批量加载数据。 - 模型定义:定义了一个名为
LeNet的类,这个类继承了torch.nn.Module。LeNet类中定义了两个主要的部分:self.conv和self.fc。self.conv包含了两个卷积层和两个最大池化层,用于从输入图片中提取特征;self.fc包含了三个全连接层,用于对提取出的特征进行分类。 - 模型训练:在训练过程中,首先将模型和数据转移到指定的设备(GPU或CPU),然后在每个epoch中,对训练数据进行遍历,计算模型的输出和损失,然后进行反向传播和参数更新。在每个epoch结束后,还会计算并打印出训练损失、训练准确率和测试准确率。
- 模型评估:使用
evaluate_accuracy函数在测试数据上评估模型的准确率。这个函数会遍历测试数据,计算模型的输出,然后比较模型的输出和真实的标签,计算出准确率。 - 模型保存:在训练结束后,使用
torch.save函数保存模型的参数。
这段代码的主要目标是训练一个LeNet模型,用于识别FashionMNIST数据集中的服装类别。
经过以上步骤,得到pt类型的模型。
60行代码,完成LeNet模型的预测脚本。
预测代码如下
import torch
from torchvision import datasets, transforms
from LeNet import LeNet
import matplotlib.pyplot as plt
import numpy as np
# 预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载FashionMNIST测试数据集
test_data = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=True)
# 选择设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将模型移动到设备上
model = LeNet()
# 加载state_dict
state_dict = torch.load('Lenet.pth')
# 将state_dict加载到模型中
model.load_state_dict(state_dict)
# 用于存储预测结果和真实标签
predicted_labels = []
true_labels = []
# 预测
model.eval() # 设置为评估模式
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1)
predicted_labels.extend(predicted.cpu().numpy())
true_labels.extend(target.cpu().numpy())
# 定义FashionMNIST类别
# classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 选择要可视化的图片数量
num_images_to_show = 10
# 选择一些随机的测试数据
indices = np.random.choice(len(predicted_labels), num_images_to_show)
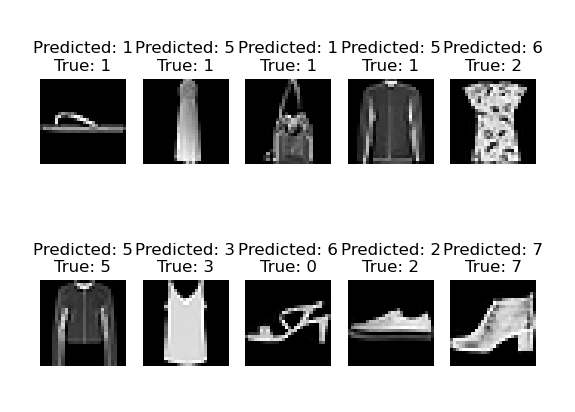
for i, index in enumerate(indices):
plt.subplot(2, num_images_to_show//2, i+1)
plt.axis('off')
plt.imshow(test_data[index][0].numpy().squeeze(), cmap='gray')
plt.title("Predicted: " + str(predicted_labels[index]) + "\nTrue: " + str(true_labels[index]))
plt.show()这段代码的主要目的是加载训练好的LeNet模型,然后使用这个模型对FashionMNIST测试集进行预测,并将预测结果进行可视化。这里是具体的步骤:
- 数据预处理和加载:首先,定义了一个预处理操作,这个操作将图片转换为张量并进行归一化。然后,使用
torchvision.datasets.FashionMNIST加载FashionMNIST测试数据集,并使用torch.utils.data.DataLoader创建数据加载器。 - 模型加载:然后,创建一个LeNet模型,并使用
torch.load函数加载预训练的模型参数。 - 预测:在预测过程中,首先将模型设置为评估模式,然后遍历测试数据,计算模型的输出,并使用
torch.max函数获取预测的类别。预测的类别和真实的类别都被保存下来,以便之后进行可视化。 - 可视化:最后,选择一些随机的测试数据,并将这些数据的图片、预测的类别和真实的类别进行可视化。这可以帮助我们直观地了解模型的预测效果。
随机选取10张图片进行结果展示:
可以看出,模型的精度不高,也有可能是现在只训练了50次。