高效的多维空间点索引算法-Geohash算法原理及实现
高效的多维空间点索引算法-Geohash算法原理及实现
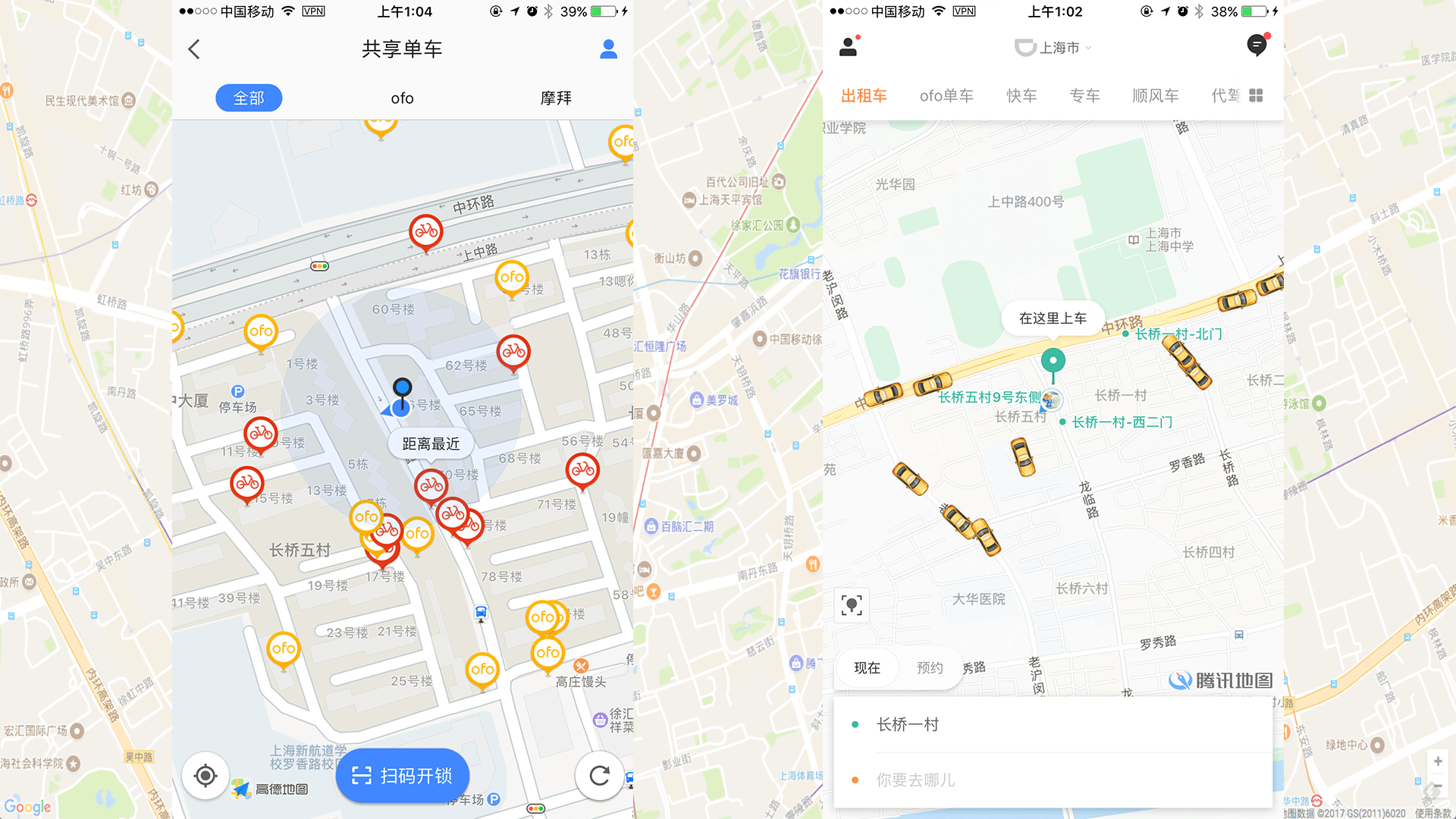
ytkz每天我们晚上加班回家,可能都会用到滴滴或者共享单车。打开 app 会看到如下的界面:
app 界面上会显示出自己附近一个范围内可用的出租车或者共享单车。假设地图上会显示以自己为圆心,5公里为半径,这个范围内的车。如何实现呢?最直观的想法就是去数据库里面查表,计算并查询车距离用户小于等于5公里的,筛选出来,把数据返回给客户端。
这种做法比较笨,一般也不会这么做。为什么呢?因为这种做法需要对整个表里面的每一项都计算一次相对距离。太耗时了。既然数据量太大,我们就需要分而治之。那么就会想到把地图分块。这样即使每一块里面的每条数据都计算一次相对距离,也比之前全表都计算一次要快很多。
问题就来了,地图上的点是二维的,有经度和纬度,这如何索引呢?如果只针对其中的一个维度,经度或者纬度进行搜索,那搜出来一遍以后还要进行二次搜索。那要是更高维度呢?三维。可能有人会说可以设置维度的优先级,比如拼接一个联合键,那在三维空间中,x,y,z 谁的优先级高呢?设置优先级好像并不是很合理。
本篇文章就来介绍1种比较通用的空间点索引算法——GeoHash 。
在最基本的层面上,GeoHash 将二维地理坐标编码成字母和数字字符串。每个字符串代表一个特定的地理矩形区域,并由该矩形区域内的所有坐标共享。因此,字符串越长,相应的矩形区域就越小、越精确。
在对地理位置进行编码时,要计算目标经纬度,以确定它们是位于原始区间的左侧还是右侧,纬度区间为[-90,90],经度区间为[-180,180]。
位于左段的点记录为 0,位于右段的点记录为 1。然后将上一步得到的区间对折,执行进一步的搜索功能,进而返回一个新的二进制编码。
当这一过程产生的二进制代码长度达到所需的精度时,再根据经度值置于偶数位、纬度值置于奇数位的规则对代码进行交错,从而产生一个新的二进制字符串。最后一步,根据 Base32 表将二进制字符串转换为字符串,从而得到精确的地理坐标 GeoHash 字符串。
通过将地球看成一个二维的平面图,然后将平面递归切分成更小的模块,然后将空间经纬度数据进行编码生成一个二进制的字符串,再通过base32将其转换为一个字符串。最终是通过比较geohash的值的相似程度查询附近目标元素。
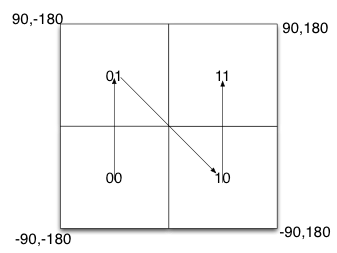
我们知道,经度范围是东经180到西经180,纬度范围是南纬90到北纬90,我们设定西经为负,南纬为负,所以地球上的经度范围就是[-180, 180],纬度范围就是[-90,90]。如果以本初子午线、赤道为界,地球可以分成4个部分。
如果纬度范围[-90°, 0°)用二进制0代表,(0°, 90°]用二进制1代表,经度范围[-180°, 0°)用二进制0代表,(0°, 180°]用二进制1代表,那么地球可以分成如下4个部分。
下面讲讲这个算法的实现。
算法实现
geohash分为编码、解码,我们先从 编码的步骤说起,即是经纬度转为geohash码。Geohash算法一共有三步。
第1步,首先将经纬度变成二进制。
经度按照左、右半区,如果经度在左半区,则为当前码为0;如果经度在左半区,则为当前码为1。更新左、右半区的范围。
纬度按照上、下半区,如果经度在下半区,则为当前码为0;如果纬度在上半区,则为当前码为1。更新上、下半区的范围。
下面以坐标 “30.280245, 120.027162 “为例说明 GeoHash 字符串的计算。首先,纬度为二进制,已按以下步骤编码:
1.将 [-90,90] 分成相等的两半。”30.280245 “位于右半部分(0,90),因此第一位为 1。
2.将 [0,90] 分成相等的两半。”30.280245 “位于左半部分(0,45),因此第二位为 0。
3.不断重复这一过程,使结果区间越来越小,两个端点越来越接近 “30.280245”。
迭代详见下图:

这些迭代一直持续到代码长度达到所需的精度为止。15 位二进制代码的完整迭代表如下:
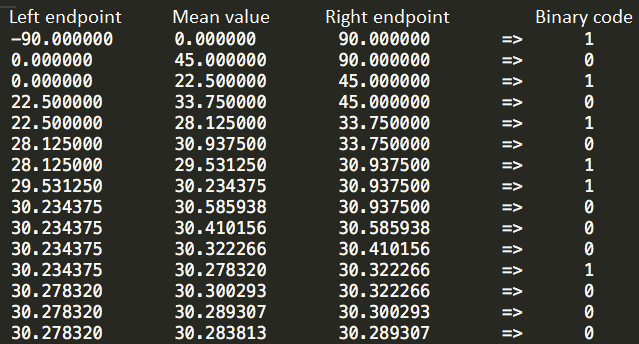
由此得到的纬度二进制代码为 10101 01100 01000。
再比如这样一个点(39.923201, 116.390705) ,纬度的范围是(-90,90),其中间值为0。对于纬度39.923201,在上半区间(0,90)中,因此得到一个1;(0,90)区间的中间值为45度,纬度39.923201小于45,在下半区间(0,45)中,因此得到一个0,依次计算下去,即可得到纬度的二进制表示,如下表:
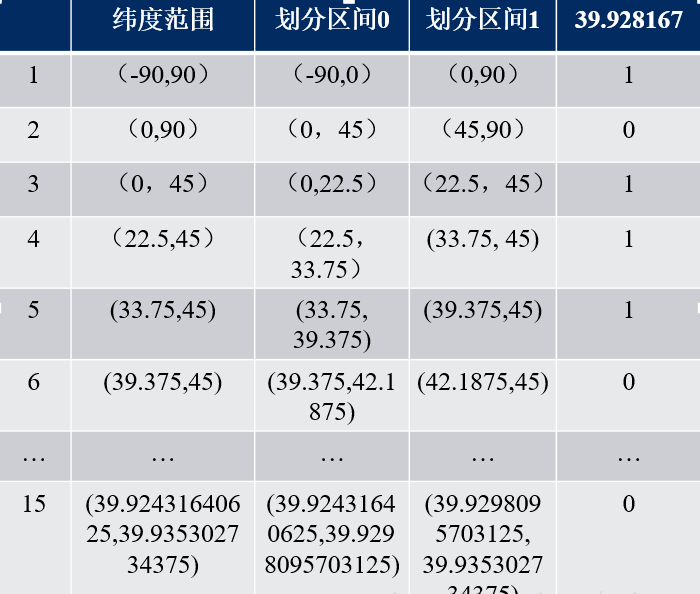
最后得到纬度的二进制表示为:
10111000110001111001同理可以得到经度116.390705的二进制表示为:
11010010110001000100第2步,就是将经纬度合并。
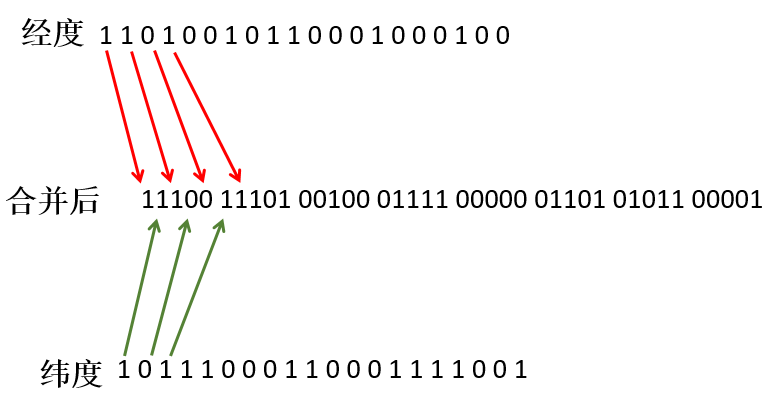
算出经纬度编码后,从高到低,奇数为经度,偶数为纬度,合并经纬度编码。
lng: 10111000110001111001
lat: 11010010110001000100
合并后:
11100 11101 00100 01111 00000 01101 01011 00001图解如下:
第3步,按照Base32进行编码
Base32编码表的其中一种如下,是用0-9、b-z(去掉a, i, l, o)这32个字母进行编码。具体操作是先将上一步得到的合并后二进制转换为10进制数据,然后对应生成Base32码。需要注意的是,将5个二进制位转换成一个base32码。
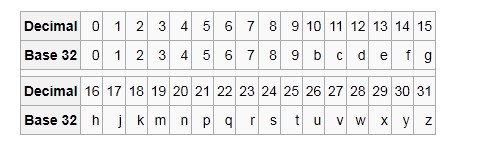
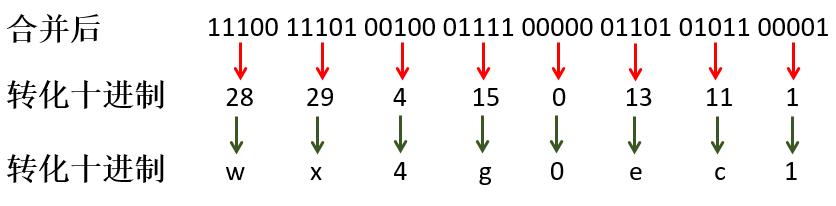
经纬度(39.923201, 116.390705)就转为了wx4g0ec1。
Geohash比直接用经纬度的高效很多,而且使用者可以发布地址编码,既能表明自己位于某个地方附近,又不至于暴露自己的精确坐标,有助于隐私保护。
- GeoHash用一个字符串表示经度和纬度两个坐标。在数据库中可以实现在一列上应用索引(某些情况下无法在两列上同时应用索引)
- GeoHash表示的并不是一个点,而是一个矩形区域
- GeoHash编码的前缀可以表示更大的区域。例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。 这个特性可以用于附近地点搜索
编码越长,表示的范围越小,位置也越精确。因此我们就可以通过比较GeoHash匹配的位数来判断两个点之间的大概距离。
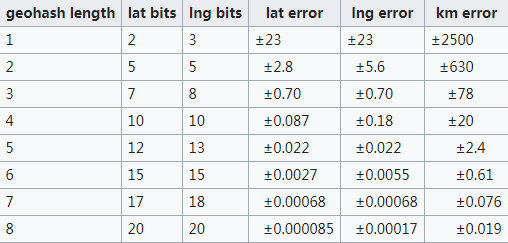
Geohash能实现什么功能?
- 地图导航; 高德地图、百度地图、腾讯地图
- 附近人功能;微信附近人、游戏附近人、滴滴打车附近的司机、美团外卖附近的商家等等
代码
def binary_to_decimal(binary_str):
decimal = 0
# 遍历二进制字符串中的每一位
for i, digit in enumerate(reversed(binary_str)):
if digit == '1':
# 如果这一位是1,则加上对应的2的幂次
decimal += 2 ** i
return decimal
def decimal_to_binary(decimal):
binary = ""
while decimal > 0:
remainder = decimal % 2
binary = str(remainder) + binary
decimal = decimal // 2
# 若不够五位,则补全五位
while len(binary) < 5:
binary = str(0) + binary
return binary
def geohash_encode(latitude, longitude, precision=12):
# 编码
lat_interval, lon_interval = (-90.0, 90.0), (-180.0, 180.0)
geohash = []
# bits = [16, 8, 4, 2, 1]
bit = 0
# ch = 0
even = True
tempstr=''
allstr = ''
while len(geohash) < precision:
if even:
mid = (lon_interval[0] + lon_interval[1]) / 2
if longitude > mid:
# ch |= bits[bit]
lon_interval = (mid, lon_interval[1])
tempstr = tempstr + '1'
else:
lon_interval = (lon_interval[0], mid)
tempstr = tempstr + '0'
else:
mid = (lat_interval[0] + lat_interval[1]) / 2
if latitude > mid:
# ch |= bits[bit]
lat_interval = (mid, lat_interval[1])
tempstr = tempstr + '1'
else:
lat_interval = (lat_interval[0], mid)
tempstr = tempstr + '0'
even = not even
if bit < 4:
bit += 1
else:
allstr += tempstr
ch = binary_to_decimal(tempstr)
geohash.append('0123456789bcdefghjkmnpqrstuvwxyz'[ch])
tempstr = ''
bit = 0
ch = 0
return ''.join(geohash)
def geohash_decode(hash):
# 解码
lat_interval, lon_interval = (-90.0, 90.0), (-180.0, 180.0)
lat_err, lon_err = 90.0, 180.0
is_longitude = True # Ture for lon , Fasle for lat
mask_ = ''
for i, c in enumerate(hash):
cd = '0123456789bcdefghjkmnpqrstuvwxyz'.index(c)
mask_ += decimal_to_binary( cd)
# for i in mask_:
for j, mask in enumerate(mask_):
if is_longitude :
if mask =='1':
lon_interval = ((lon_interval[0] + lon_interval[1]) / 2, lon_interval[1])
else:
lon_interval = (lon_interval[0], (lon_interval[0] + lon_interval[1]) / 2)
lon_err /= 2
else:
if mask =='1':
lat_interval = ((lat_interval[0] + lat_interval[1]) / 2, lat_interval[1])
else:
lat_interval = (lat_interval[0], (lat_interval[0] + lat_interval[1]) / 2)
lat_err /= 2
is_longitude = not is_longitude
lat = (lat_interval[0] + lat_interval[1]) / 2
lon = (lon_interval[0] + lon_interval[1]) / 2
return (lat, lon), (lat_err, lon_err)
if __name__ == '__main__':
# 示例
hash = geohash_encode(23.2296756, 110.0122287)
print("Geohash:", hash)
decoded, error = geohash_decode(hash)
print("Decoded:", decoded)
print("Error:", error)
输出为:
wknhpku6wtrk验证以上代码的准确性
通过第三方python库进行验证,安装python-geohash。
pip install python-geohash完成安装后进行下一步。
import geohash
lat = 23.2296756
lon = 110.0122287
p = 12
geohash_str = geohash.encode(lat, lon, p)输出为:
'wknhpku6wtrk'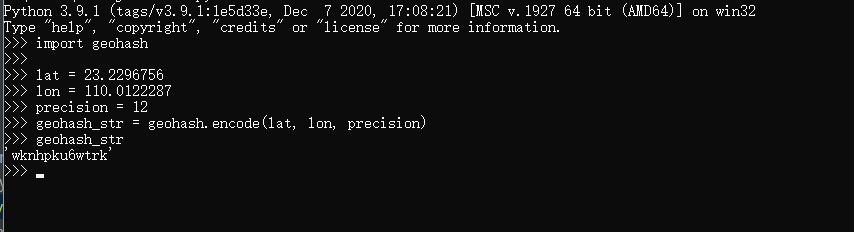
二者结果保持一致,从侧面说明了我们写的代码的准确性。
Geohash 的优缺点
Geohash 的优点很明显,它利用 Z 阶曲线进行编码。而 Z 阶曲线可以将二维或者多维空间里的所有点都转换成一维曲线。在数学上成为分形维。并且 Z 阶曲线还具有局部保序性。
Z 阶曲线通过交织点的坐标值的二进制表示来简单地计算多维度中的点的z值。一旦将数据被加到该排序中,任何一维数据结构,例如二叉搜索树,B树,跳跃表或(具有低有效位被截断)哈希表 都可以用来处理数据。通过 Z 阶曲线所得到的顺序可以等同地被描述为从四叉树的深度优先遍历得到的顺序。
这也是 Geohash 的另外一个优点,搜索查找邻近点比较快。
Geohash 的缺点之一也来自 Z 阶曲线。
Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变。
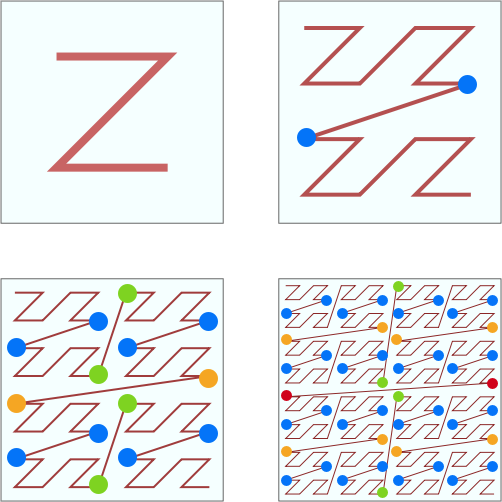
看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。
Geohash 的另外一个缺点是,如果选择不好合适的网格大小,判断邻近点可能会比较麻烦。
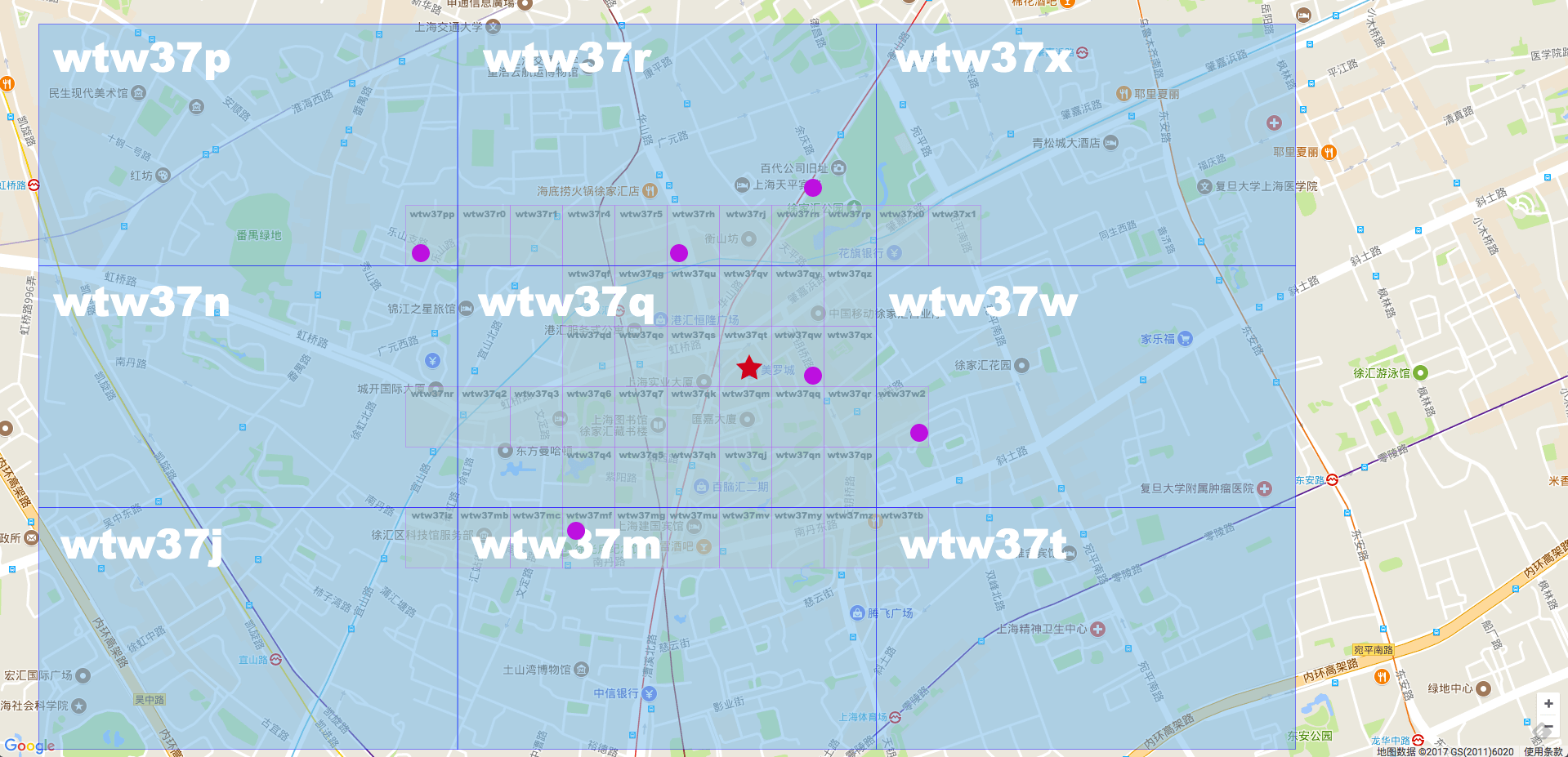
看上图,如果选择 Geohash 字符串为6的话,就是蓝色的大格子。红星是美罗城,紫色的圆点是搜索出来的目标点。如果用 Geohash 算法查询的话,距离比较近的可能是 wtw37p,wtw37r,wtw37w,wtw37m。但是其实距离最近的点就在 wtw37q。如果选择这么大的网格,就需要再查找周围的8个格子。
如果选择 Geohash 字符串为7的话,那变成黄色的小格子。这样距离红星星最近的点就只有一个了。就是 wtw37qw。
如果网格大小,精度选择的不好,那么查询最近点还需要再次查询周围8个点。
小结
geohash 是一种简化大量点数据与面数据间空间关系计算的方法,本质上属于空间索引技术。在地理信息系统 (GIS) 领域中,存在多种高效的空间索引技术,如 R 树及其变体(R+树、R*树)、四叉树、K-D 树和网格索引等,每种技术都有其独特的应用场景和优势。
除了 geohash,还有一些先进的空间索引方法被广泛采用,例如谷歌的 S2 算法以及 Uber 的 H3 算法。尽管 geohash 在处理空间点数据方面表现出色,但在性能上通常不如谷歌的 S2 算法。因此,许多大型系统倾向于使用 S2 算法进行空间数据索引。
对于更复杂的空间数据结构,如多维空间中的线、面或多边形,这些对象由多个空间点组成,如街道、建筑物、铁路或河流等,我们需要考虑如何高效地存储和检索这类信息。在这种情况下,传统的 B+树可能不再适用,而需要采用专门针对多维空间数据设计的数据结构,如 R 树及其变体。
R 树能够有效处理多维空间数据,支持复杂的查询类型,如范围查询和最近邻查询。通过使用 R 树,我们可以在保持较高查询效率的同时,对多维空间对象进行有效的管理和检索。
由于这部分内容涉及较为复杂的理论和技术细节,这里先不深入探讨。未来有机会时,我们可以详细分享一篇关于“多维空间多边形索引算法”的文章,探讨如何有效地处理和搜索这些复杂的空间数据结构。