神经网络的解释,我想到了遥感指数
神经网络的解释,我想到了遥感指数
ytkz今天在网上冲浪,看到了一个号称是最好懂的神经网络解释。我读完之后立马想到了遥感植被指数。
神经网络是 AI 的算法基础。
前些天,我在美国科普网站《量子杂志》(Quanta Magazine),读到一篇科普文章,用一个浅显的例子 + 插图,解释了神经网络,堪称我见过的最好懂的教程。
下面就是我整理出来的中文版。
1、

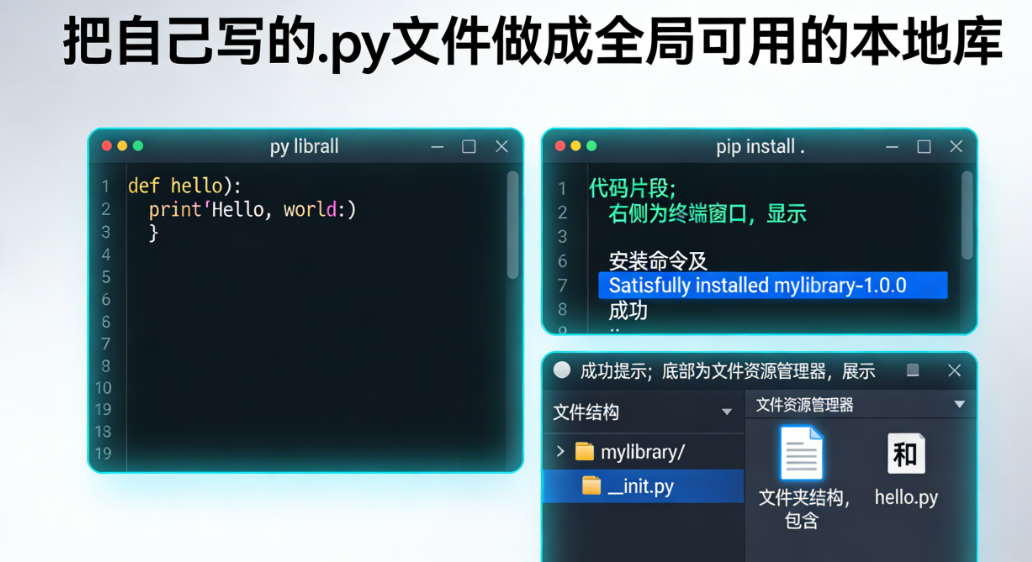
你的计算机里有一堆照片,你想要从中找出猫的照片,应该怎么做?
你很快意识到,这其实是一个机器分类问题,计算机要把照片分成两类:一类是猫,另一类不是猫。
2、
让我们把这个问题想成一张地图,中间有一条分界线,把地图分成两个国家。
你的任务是,找出这条分界线的确切位置。这样的话,给出任意一个点,你就知道它在分界线的左边还是右边。
3、
作为已知条件,地图上很多点的归属,是已知的。比如上图中,三角点属于 A 国,方块点属于 B 国。
你要做的就是,从这些点推测出分界线。
4、
我们可以建立一个数学函数(上图的点 N),处理这个问题。
这个函数接受两个参数,分别是每个点的 x 坐标和 y 坐标,函数的返回值是0~1之间的一个值,表示该点有多大概率属于当前国家。
5、
你就用已知的点,去训练这个函数。
计算机自动根据每次训练的误差,调整每个参数的权重值,最终得到一条最接近的分界线。
6、
笔直的分界线只是最理想的情况,现实世界中,分界线更可能是七拐八弯的曲线。
7、
这时,只用一个函数来确定分界线,就不太够了。你需要多个函数,从不同角度进行判断。
8、
判断过程甚至需要分阶段进行,也就是需要多层函数。
这些函数组成的网络,很像人类的神经系统,所以称为神经网络。每个函数就是网络中的一个神经元。
9、
好了,现在再回到猫的照片。我们同样需要建立一个函数,来判断照片是猫的概率。
地图分界线的函数只需要 X 和 Y 两个参数,猫照片的函数就不行了,需要把整张照片输入进去。假如照片大小是2500个像素,那么函数就有2500个参数。
10、
函数的参数个数,可以看成空间的维度,2个参数就是二维空间,2500个参数就是2500维的空间。
猫照片的函数就是在2500维空间里面,通过大量训练,找到一条分界线,从而算出任意一张照片落在线内的概率有多大。
在神经网络大火之前,遥感图像分类主要依赖人为设计的“遥感指数”或者是机器学习,其中最具代表性的是归一化植被指数(NDVI)。
这种指数通过计算近红外波段与可见光波段反射率的差值与其和的比值((NIR-R)/(NIR+R)),将卫星图像中的像素点划分为“植被”或“非植被”两类。
其原理基于植被在近红外波段的高反射特性,而水体、土壤等则呈现相反的光谱响应,因此通过设定阈值(如NDVI>0.2)即可实现二元分类。
然而,这种人为划定的线性分界线存在明显局限性。它仅适用于简单的二元分类场景(如植被检测),无法处理更复杂的多类别区分问题(例如区分水稻、小麦和玉米)。
这是因为不同植被类型的光谱特征在多维空间中可能存在重叠或非线性分布,而NDVI这类线性公式无法捕捉这些细微差异。
神经网络的引入解决了这一瓶颈。与人为设定固定规则的遥感指数不同,神经网络能够通过大量样本自动学习多维特征空间中的复杂非线性边界。
例如,卷积神经网络(CNN)可通过多层卷积和池化操作提取光谱、纹理及空间特征,自适应地构建高维分类界面。
这种“端到端”的学习方式不仅突破了传统指数对简单线性关系的依赖,还能融合多源信息(如时序NDVI曲线、地形数据等),显著提升分类精度。
因此,传统遥感指数可视为神经网络的“初级形态”——一种基于人工先验的线性判别工具,而神经网络则是通过数据驱动实现复杂非线性分类的智能系统。
两者的核心差异在于:前者依赖人类经验划定固定规则,后者通过自主学习优化分类边界,从而适应更精细的地物识别需求