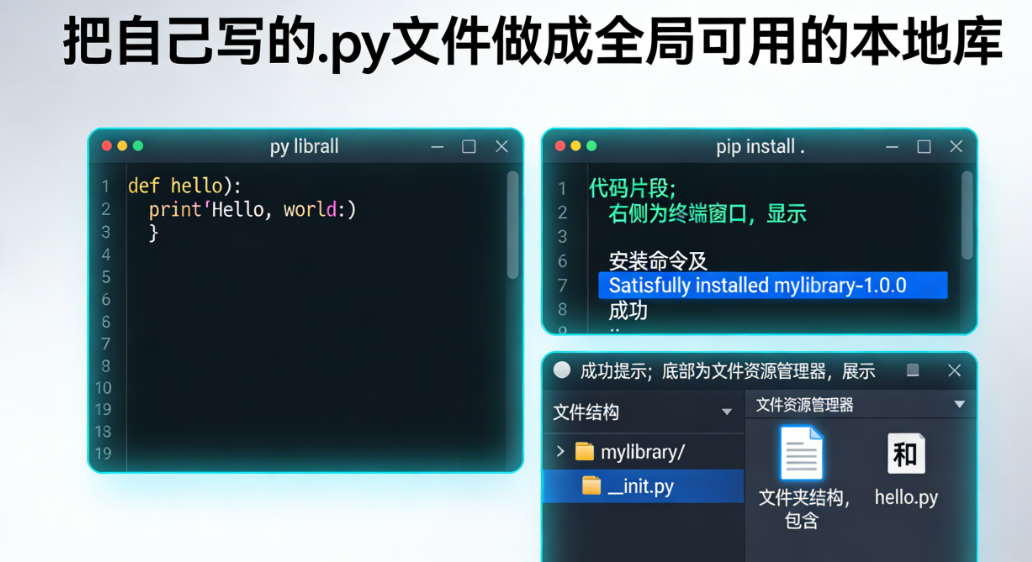
使用Meta的Segment Anything Model (SAM) 加速图像分割标注

使用Meta的Segment Anything Model (SAM) 加速图像分割标注
ytkz作为一名遥感行业从业者,深知获取高质量标注数据集的痛点。针对新物体类别的分割任务,往往需要手动收集并标注成千上万张图像。相比物体检测的边界框标注,像素级分割的精确度要求更高,工作量成倍增加。
Meta的Segment Anything Model (SAM) 模型提供了一种革命性方法,能大幅加速各种物体的标注过程。下面,我们来深入探讨这个出色模型的细节。
主要内容
- 什么是Segment Anything Model (SAM)?
- 为什么需要SAM?
- SAM的架构
- SAM模型训练
- 结果分析
- SAM 2的新特性
什么是Segment Anything Model (SAM)?
SAM 是Meta AI开发的最先进AI模型,能在图像或视频中识别并分割任意物体。作为计算机视觉的基础模型,它无需额外训练即可泛化到新物体类别和任务。
本质上,SAM 执行图像分割任务,即将图像分区成多个物体段落。但它超越传统分割模型的地方在于:
- 通用性:能分割任何物体,即使训练数据中未包含。
- 交互性:用户可通过点、框或文本等提示引导模型。
- 实时性:能实时生成高质量掩码,适合交互应用。
- 适应性:无需大量重训,即可微调特定任务或领域。
Meta 通过三个互连组件构建了这个分割基础模型:
- 可提示的分割任务。
- SAM模型,用于数据标注,并通过提示工程实现零样本转移到各种任务。
- 数据引擎,用于收集SA-1B数据集(超过10亿个掩码)。
SAM的成功依赖任务、模型和数据三要素。我们需要回答三个关键问题:
- 什么任务能实现零样本泛化?
- 对应的模型架构是什么?
- 什么数据能驱动这个任务和模型?
这些问题相互纠缠,需要整体解决方案。我们从定义一个足够通用的可提示分割任务入手,这要求模型支持灵活提示,并实时输出掩码以便交互使用。为训练模型,我们需要多样化、大规模数据源。但网络上缺乏海量分割数据,Meta因此构建了“数据引擎”——通过模型辅助数据收集,并用新数据迭代改进模型。
在我的理解中,SAM的核心创新在于将提示工程从NLP扩展到视觉领域,这让我联想到CLIP模型的零样本能力。
为什么需要SAM?
数据标注难上加难,我亲身经历过四年分割模型工作。现实数据集不像基准测试那样完美标注。
我用过免费和专业工具标注分割数据,各有局限。免费工具多限于多边形工具,通过点击物体边界绘制多边形,但问题有二:(1) 非像素级精确;(2) 标注小物体(如混凝土裂缝)异常困难。
现有计算机视觉模型的局限包括:
- 范围有限:多针对特定物体类别。
- 灵活性不足:难以处理新奇物体。
- 计算开销高:不适合实时应用。
- 训练需求大:适应新任务需大量重训。
SAM 通过提供通用、适应性强且高效的解决方案,解决了这些痛点。
为什么NLP基础模型众多,而视觉任务少?NLP模型创建相对容易,但视觉受标注瓶颈制约。零样本提示在这里大显身手,帮助解决标注难题。
SAM填补了视觉领域的“基础模型空白”,类似于BERT对NLP的影响。它不只加速标注,还开启了提示驱动的视觉AI新时代,潜在应用包括医疗影像分析和自动驾驶。
SAM的架构
为向分割模型指示物体位置,我们有多种提示方式:点、边界框、粗略区域图或文本提示。为实现这种灵活性,先用图像编码器将图像转为嵌入,然后整合各种提示。

SAM 使用预训练的Vision Transformer (ViT,基于掩码自编码器),稍作调整以处理高分辨率输入。图像编码器每图像运行一次,可在提示前预计算。
提示类型多样:稀疏提示(点、框、文本)用位置编码加学习嵌入表示;稠密提示(掩码)用卷积嵌入并与图像嵌入逐元素相加;自由文本用CLIP的现成文本编码器。
解码器采用修改的Transformer解码器。训练使用Focal和Dice损失组合。

SAM模型训练
训练分三阶段:
初始阶段:用公开数据,人力修正错误掩码并重训。产生12万图像、430万掩码。

半自动阶段:标注员标注详细未标签物体,平均掩码从44增至72。

全自动阶段:用32x32网格点提示,标注部分、子部分和整体。产生超11亿掩码,形成SA-1B数据集。

结果分析


SAM 2、SAM3的新特性?
Meta最近发布的SAM 2\ SAM3主要针对视频增强,核心概念类似,但有优化:
记忆机制:添加记忆编码器、记忆库和注意力模块,跨帧存储信息,提升视频跟踪,尤其处理遮挡或物体重现。
多掩码歧义解决:在复杂场景生成多个掩码预测,处理重叠物体。
改进训练数据:用SA-V数据集训练,更丰富多样,包含更多视频和标注。
SAM 2的记忆机制借鉴了序列模型如RNN的思想,标志着分割从静态向动态演进。
目前我的测试中,SAM2的图像分割在细节方面不如SAM。SAM3我还没开始测试。
你的点赞和分享是最大动力。别忘了关注我,快乐学习。