不校正也能看范围?手把手教你用Python和RPC秒提卫星影像边框
不校正也能看范围?手把手教你用Python和RPC秒提卫星影像边框
ytkz大家好,我是小白。
最近处理国产卫星数据(比如高分、吉林一号这些),经常遇到一个痛点: 拿到的原始数据(L1级)是不带地理坐标的 。
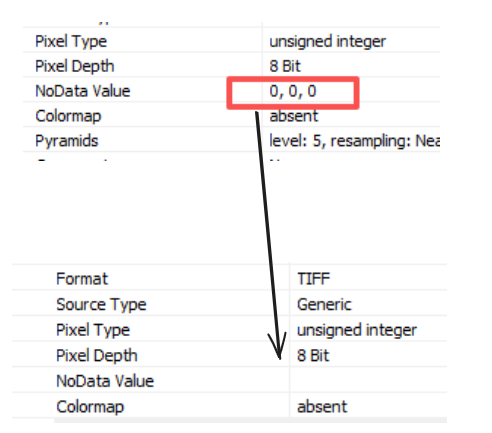
直接拖进ArcGIS或QGIS里?arcgis就自动使用同一个目录下的rpc文件对金字塔文件进行几何校正。如果你想看它到底覆盖了地球上哪块地,通常的做法是做“正射纠正”——但这玩意儿费时费力啊,几百景数据跑下来,电脑风扇都能起飞。
其实,如果我们只是想“知道它在哪”,完全不需要处理图像像素,只需要读懂它的“身份证”—— RPC文件 就够了。
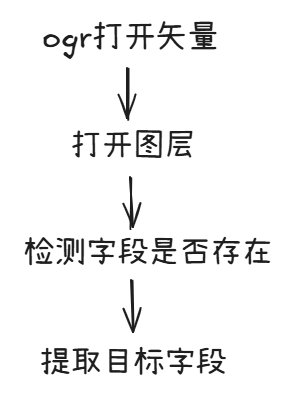
今天给大家分享一段Python代码,逻辑很硬核,但用起来很爽。它的功能很简单: 读取原始影像的RPC参数,直接算出影像的四个角点坐标,生成一个Shapefile框框。
为什么要搞这么复杂?
很多同学会问:“直接读Tiff里的元数据不行吗?”
对于已经纠正过的产品(L2级以上),当然可以。但对于原始影像,相机和地面的关系是非常复杂的几何投影,并没有简单的Affine Transform(仿射变换),而是通过有理多项式系数(RPC)来描述的。
简单说,RPC就是一个超级复杂的数学公式,告诉我们: 图像上的第几行第几列,对应地面的经度、纬度、高度。
代码逻辑拆解
完整的代码我放在文后。
这份代码主要干了三件事,我们拆开来看看:
- 啃下“RPC”这块硬骨头
代码里写了一个 parse_rpc_file 函数。
这也是最烦人的地方。不同卫星厂商给的RPC文件格式千奇百怪!有的用冒号分隔,有的用等号,有的带单位(meters, pixels),有的甚至把系数拆成 lineNumCoef_1 到 _20 。
这段代码用了比较暴力的正则表达式(Regex)和逻辑判断,把这些乱七八糟的格式统一清洗,提取出我们需要的90个核心系数(20个分子+20个分母,乘上行列经纬高)。
小白划重点 :数据清洗往往比算法本身还累,这段解析代码算是个“万能钥匙”,大部分国产卫星的RPC文本都能读。
- 最核心的数学魔法:从图像反算经纬度
在 RPCModel 类里,有一个 localization 函数。
这里有个坑:RPC模型通常是 正向 的(给经纬高 -> 算图像行列号)。但我们现在的需求是 反向 的(已知图像的四个角点 -> 求地面的经纬度)。
由于公式太复杂,没法直接反解。代码里用了一个聪明的办法: 牛顿迭代法(Newton-Raphson) 。
- 第一步 :先瞎猜一个经纬度(比如0,0)。
- 第二步 :用正向公式算一下这个经纬度对应的图像坐标。
- 第三步 :看算出来的坐标和真实坐标差多少(残差)。
- 第四步 :根据偏导数(雅可比矩阵)调整经纬度,再试一次。
代码里的 localization_iterative 就是在干这事,通常循环几次,误差就小于0.0001像素了,非常精准。
生成“脚印”(Footprint)
最后一步就简单了:读取Tiff影像的宽和高(比如 12000 x 12000)。
- 提取四个顶点的图像坐标:(0,0), (宽,0), (宽,高), (0,高)。
- 把这四个点扔进上面的“数学魔法”里,算出四个经纬度坐标。
用 geopandas 和 shapely 库,把这四个点连成一个多边形(Polygon),保存成 .shp 文件。
应用场景
这代码写出来有啥用?
快速建立索引库 :如果你硬盘里躺着几TB的原始数据,不想一个个打开看,用这个脚本跑一遍,生成一堆框框,往GIS里一拖,瞬间知道谁覆盖了哪。
- 自动化处理管线 :作为预处理的第一步,先算范围,再做后续的切片或纠正。
怎么用?
代码依赖这几个库,装一下就行:
pip install rasterio geopandas shapely numpy运行的时候,只需要传入三个路径:
python generate_footprint.py 原始影像.tif 配套的.rpc 输出的.shp碎碎念
其实这份代码里把高程(Height)默认设为了 HEIGHT_OFF (平均高程)。在平原地区这完全够用了,但在落差巨大的山区,如果不引入DEM(数字高程模型)参与计算,会有几十米甚至上百米的偏差。不过作为“索引框”来说,这个精度绝对是够用了。
代码我放在下面了,大家可以拿去试试,特别是手里有一堆国产卫星数据不知道怎么管理的同学,绝对是神器!
完整代码如下:
import os
import re
import numpy as np
import rasterio
import geopandas as gpd
from shapely.geometry import Polygon
# L1影像加上rpc文件,直接生成影像的地理几何范围。
# ==================== RPC Model Implementation ====================
def apply_poly(poly, x, y, z):
"""
Evaluates a 3-variables polynom of degree 3 on a triplet of numbers.
"""
out = 0
out += poly[0]
out += poly[1] * y + poly[2] * x + poly[3] * z
out += poly[4] * y * x + poly[5] * y * z + poly[6] * x * z
out += poly[7] * y * y + poly[8] * x * x + poly[9] * z * z
out += poly[10] * x * y * z
out += poly[11] * y * y * y
out += poly[12] * y * x * x + poly[13] * y * z * z + poly[14] * y * y * x
out += poly[15] * x * x * x
out += poly[16] * x * z * z + poly[17] * y * y * z + poly[18] * x * x * z
out += poly[19] * z * z * z
return out
def apply_rfm(num, den, x, y, z):
"""
Evaluates a Rational Function Model (rfm).
"""
return apply_poly(num, x, y, z) / apply_poly(den, x, y, z)
class RPCModel:
def __init__(self, d):
self.row_offset = float(d['LINE_OFF'])
self.col_offset = float(d['SAMP_OFF'])
self.lat_offset = float(d['LAT_OFF'])
self.lon_offset = float(d['LONG_OFF'])
self.alt_offset = float(d['HEIGHT_OFF'])
self.row_scale = float(d['LINE_SCALE'])
self.col_scale = float(d['SAMP_SCALE'])
self.lat_scale = float(d['LAT_SCALE'])
self.lon_scale = float(d['LONG_SCALE'])
self.alt_scale = float(d['HEIGHT_SCALE'])
self.row_num = self._parse_coeff(d['LINE_NUM_COEFF'])
self.row_den = self._parse_coeff(d['LINE_DEN_COEFF'])
self.col_num = self._parse_coeff(d['SAMP_NUM_COEFF'])
self.col_den = self._parse_coeff(d['SAMP_DEN_COEFF'])
# Optional: Lat/Lon coefficients for inverse projection (if available)
# Often RPCs only provide Ground -> Image (Forward), so we use iterative for Image -> Ground (Inverse)
def _parse_coeff(self, coeff_str):
if isinstance(coeff_str, list):
return [float(x) for x in coeff_str]
# Remove parentheses and split
s = coeff_str.replace('(', '').replace(')', '').replace(',', ' ')
return [float(x) for x in s.split()]
def localization(self, col, row, alt):
"""
Image (col, row) + Alt -> Ground (Lon, Lat)
"""
ncol = (col - self.col_offset) / self.col_scale
nrow = (row - self.row_offset) / self.row_scale
nalt = (alt - self.alt_offset) / self.alt_scale
lon, lat = self.localization_iterative(ncol, nrow, nalt)
lon = lon * self.lon_scale + self.lon_offset
lat = lat * self.lat_scale + self.lat_offset
return lon, lat
def localization_iterative(self, col, row, alt):
"""
Iterative estimation of (lon, lat) from (col, row, alt).
Normalized coordinates.
"""
# Initial guess: (0, 0) in normalized ground coordinates
lon = 0.0
lat = 0.0
# Iteration parameters
EPS = 1e-6
MAX_ITER = 100
for i in range(MAX_ITER):
# Calculate (col, row) for current (lon, lat)
x0 = apply_rfm(self.col_num, self.col_den, lat, lon, alt)
y0 = apply_rfm(self.row_num, self.row_den, lat, lon, alt)
# Partial derivatives (numerical approximation)
delta = 1e-5
x_dlat = (apply_rfm(self.col_num, self.col_den, lat + delta, lon, alt) - x0) / delta
x_dlon = (apply_rfm(self.col_num, self.col_den, lat, lon + delta, alt) - x0) / delta
y_dlat = (apply_rfm(self.row_num, self.row_den, lat + delta, lon, alt) - y0) / delta
y_dlon = (apply_rfm(self.row_num, self.row_den, lat, lon + delta, alt) - y0) / delta
# Jacobian
J = np.array([[x_dlon, x_dlat], [y_dlon, y_dlat]])
# Error
err_col = col - x0
err_row = row - y0
err = np.array([err_col, err_row])
# Update (Newton-Raphson)
# [dlon, dlat] = J^-1 * err
try:
update = np.linalg.solve(J, err)
except np.linalg.LinAlgError:
break
lon += update[0]
lat += update[1]
if np.linalg.norm(update) < EPS:
break
return lon, lat
# ==================== RPC Reading ====================
def parse_rpc_file(rpc_path):
with open(rpc_path, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
data = {}
# Normalize content: remove units and common noise
# We do this on a line-by-line basis to be safe
lines = content.split('\n')
cleaned_lines = []
for line in lines:
# Remove comments
line = line.split('//')[0]
# Remove units (case insensitive)
line = re.sub(r'(pixels|degrees|meters)', '', line, flags=re.IGNORECASE)
# Remove semi-colons
line = line.replace(';', '')
cleaned_lines.append(line)
cleaned_content = '\n'.join(cleaned_lines)
# Define regex patterns for various formats
# 1. "Key = Value" or "Key: Value"
# We use a broad pattern and then map keys
# Key mapping to standard names
key_map = {
'LINEOFFSET': 'LINE_OFF', 'LINE_OFF': 'LINE_OFF',
'SAMPOFFSET': 'SAMP_OFF', 'SAMPLEOFFSET': 'SAMP_OFF', 'SAMP_OFF': 'SAMP_OFF',
'LATOFFSET': 'LAT_OFF', 'LAT_OFF': 'LAT_OFF',
'LONGOFFSET': 'LONG_OFF', 'LONG_OFF': 'LONG_OFF',
'HEIGHTOFFSET': 'HEIGHT_OFF', 'HEIGHT_OFF': 'HEIGHT_OFF',
'LINESCALE': 'LINE_SCALE', 'LINE_SCALE': 'LINE_SCALE',
'SAMPSCALE': 'SAMP_SCALE', 'SAMPLESCALE': 'SAMP_SCALE', 'SAMP_SCALE': 'SAMP_SCALE',
'LATSCALE': 'LAT_SCALE', 'LAT_SCALE': 'LAT_SCALE',
'LONGSCALE': 'LONG_SCALE', 'LONG_SCALE': 'LONG_SCALE',
'HEIGHTSCALE': 'HEIGHT_SCALE', 'HEIGHT_SCALE': 'HEIGHT_SCALE',
# Coefficients
'LINENUMCOEF': 'LINE_NUM_COEFF', 'LINE_NUM_COEFF': 'LINE_NUM_COEFF',
'LINEDENCOEF': 'LINE_DEN_COEFF', 'LINE_DEN_COEFF': 'LINE_DEN_COEFF',
'SAMPNUMCOEF': 'SAMP_NUM_COEFF', 'SAMP_NUM_COEFF': 'SAMP_NUM_COEFF',
'SAMPDENCOEF': 'SAMP_DEN_COEFF', 'SAMP_DEN_COEFF': 'SAMP_DEN_COEFF'
}
# 1. Try parsing line by line for simple key-value pairs
for line in cleaned_lines:
line = line.strip()
if not line: continue
# Split by first : or =
parts = re.split(r'[:=]', line, maxsplit=1)
if len(parts) == 2:
k = parts[0].strip().upper()
v = parts[1].strip()
# Check if key is in our map
if k in key_map:
std_key = key_map[k]
# If value is a list of numbers (coefficients), keep it as string for now
data[std_key] = v
# Handle indexed coefficients like "lineNumCoef_1: 0.001" (sometimes split across lines)
# But the user provided format suggests "KEY: VALUE".
# If coefficients are formatted as "LINE_NUM_COEFF: 1 2 3 ...", this will work.
# 2. If coefficients are still missing, try regex for blocks (e.g. inside parenthesis)
coeff_keys = ['LINE_NUM_COEFF', 'LINE_DEN_COEFF', 'SAMP_NUM_COEFF', 'SAMP_DEN_COEFF']
for std_key in coeff_keys:
if std_key not in data:
# Try to find "Key = ( ... )" or "Key: ( ... )"
# Possible raw keys: lineNumCoef, LINE_NUM_COEFF
possible_raw_keys = [k for k, v in key_map.items() if v == std_key]
for raw_key in possible_raw_keys:
# Pattern: RawKey followed by optional whitespace, : or =, optional whitespace, ( or [, capture content, ) or ]
pattern = re.compile(re.escape(raw_key) + r'\s*[:=]?\s*[(\[]\s*(.*?)\s*[)\]]', re.DOTALL | re.IGNORECASE)
match = pattern.search(content) # Use original content to capture newlines if needed
if match:
val = match.group(1).replace('\n', ' ').replace('\r', ' ')
data[std_key] = val
break
# 3. Handle case where coefficients are listed with indices (e.g. lineNumCoef_1: val)
# This is common in some report files.
# We aggregate them into a list.
for std_key in coeff_keys:
if std_key not in data:
# Look for 20 separate entries
# e.g. sampNumCoef_1 ... sampNumCoef_20
# Identify the base name prefix from key_map (reversed)
# Simplified: look for "SAMP_NUM_COEFF_n" or "sampNumCoef_n"
# Heuristic: Check for keys ending in _1 to _20 in the cleaned lines
coeffs = []
found_all = True
# Determine prefix used in file (e.g. "LINE_NUM_COEFF_" or "lineNumCoef_")
# We search line by line
collected = {} # index -> value
# Regex to match "Key_(\d+)"
# We iterate all mapped keys that map to std_key
possible_prefixes = [k for k, v in key_map.items() if v == std_key and '_' not in k[-2:]] # avoid _1 matches in map
# Add variations with underscore
prefixes_to_check = possible_prefixes + [p + '_' for p in possible_prefixes]
for line in cleaned_lines:
parts = re.split(r'[:=]', line, maxsplit=1)
if len(parts) != 2: continue
k = parts[0].strip().upper()
v = parts[1].strip()
# Check if k matches PREFIX + digits
# or PREFIX + digits (without underscore if prefix has it?)
# Let's just use regex on the Key
m = re.match(r'([A-Z_a-z]+)[_]?(\d+)$', k)
if m:
base = m.group(1)
idx = int(m.group(2))
if idx < 1 or idx > 20: continue
# Check if base maps to our std_key
# base might be "LINE_NUM_COEFF" or "lineNumCoef"
# The base extracted by regex might consume the underscore if present in the middle
# e.g. LINE_NUM_COEFF_1 -> base=LINE_NUM_COEFF, idx=1.
# We need to handle the case where base ends with _ and the regex swallowed it into group 1 or not?
# Regex `([A-Z_a-z]+)[_]?(\d+)$`:
# If string is "LINE_NUM_COEFF_1"
# Group 1 could be "LINE_NUM_COEFF_" and Group 2 is "1" IF `[_]?` wasn't there?
# No, `+` is greedy. `[A-Z_a-z]+` will match `LINE_NUM_COEFF_`.
# Then `[_]?` matches nothing. Then `(\d+)` matches `1`.
# So base is `LINE_NUM_COEFF_`.
# If base is `LINE_NUM_COEFF_`, `key_map.get('LINE_NUM_COEFF_')` is None.
# But `key_map.get('LINE_NUM_COEFF')` is Valid.
# Strip trailing underscore from base if present
if base.endswith('_'):
base = base[:-1]
if key_map.get(base) == std_key:
collected[idx] = v
if len(collected) == 20:
# reconstruct list
sorted_coeffs = [collected[i] for i in range(1, 21)]
data[std_key] = " ".join(sorted_coeffs)
# Check for missing keys
required = ['LINE_OFF', 'SAMP_OFF', 'LAT_OFF', 'LONG_OFF', 'HEIGHT_OFF',
'LINE_SCALE', 'SAMP_SCALE', 'LAT_SCALE', 'LONG_SCALE', 'HEIGHT_SCALE',
'LINE_NUM_COEFF', 'LINE_DEN_COEFF', 'SAMP_NUM_COEFF', 'SAMP_DEN_COEFF']
missing = [k for k in required if k not in data]
if missing:
print(f"Warning: Missing RPC keys: {missing}")
# Debug: print first few lines of content to see what's wrong
print("First 10 lines of RPC file:")
print('\n'.join(lines[:10]))
return data
# ==================== Main Logic ====================
def generate_footprint(tif_path, rpc_path, output_shp_path):
print(f"Processing {tif_path} with RPC {rpc_path}...")
# 1. Read Image Dimensions
try:
with rasterio.open(tif_path) as src:
width = src.width
height = src.height
print(f"Image size: {width} x {height}")
except Exception as e:
print(f"Error reading TIFF: {e}")
return
# 2. Parse RPC
try:
rpc_data = parse_rpc_file(rpc_path)
rpc_model = RPCModel(rpc_data)
except Exception as e:
print(f"Error parsing RPC: {e}")
return
# 3. Calculate Corners (Image -> Ground)
# Coordinates: (0,0), (width, 0), (width, height), (0, height)
# Assuming average height (HEIGHT_OFF) or 0?
# Usually HEIGHT_OFF is a good approximation if we don't have DEM.
avg_height = rpc_model.alt_offset
corners_img = [
(0, 0),
(width, 0),
(width, height),
(0, height)
]
corners_geo = []
for col, row in corners_img:
lon, lat = rpc_model.localization(col, row, avg_height)
corners_geo.append((lon, lat))
# Close the ring
corners_geo.append(corners_geo[0])
print(f"Calculated corners (Lon, Lat): {corners_geo}")
# 4. Create Shapefile
try:
poly = Polygon(corners_geo)
gdf = gpd.GeoDataFrame({'geometry': [poly]}, crs="EPSG:4326")
gdf.to_file(output_shp_path, driver='ESRI Shapefile')
print(f"Successfully saved shapefile to {output_shp_path}")
except Exception as e:
print(f"Error creating shapefile: {e}")
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Generate footprint SHP from Raw TIFF and RPC.")
parser.add_argument("tif", help="Path to raw TIFF file")
parser.add_argument("rpc", help="Path to RPC file")
parser.add_argument("shp", help="Path to output Shapefile")
args = parser.parse_args()
generate_footprint(args.tif, args.rpc, args.shp)
关注“小白说遥感”,我们要硬核,也要有趣。