
引言遥感技术通过卫星影像、航空摄影和激光雷达等非接触式手段,获取地球表面的空间和光谱信息,广泛应用于环境监测、农业估产、城市规划和灾害评估等领域。Python凭借其强大的科学计算生态和灵活的编程能力,已成为遥感数据处理的首选工具。《Learning Geospatial Analysis with Python》(第七章“Python and Remote Sensing”)系统梳理了遥感数据处理的完整流程,从影像预处理到高级分析,为开发者提供了实用指南。
本文将通过详细的代码示例和实际案例,深入解析遥感影像处理的核心技术,包括波段操作、光谱指数计算、监督分类和变化检测。我们还将探讨AI辅助开发(如ChatGPT生成脚本)、GPU加速和分布式计算等前沿实践,帮助开发者构建高效、可靠的遥感分析工作流。
一、遥感数据处理核心工具库Python遥感分析依赖一系列功能强大的库,覆盖栅格数据处理、数值计算、机器学习和可视化。以下是核心工具及其典型应用场景:
库名
核心功能
典型场景
GDAL
栅格/矢量数据读写、投影转换
卫星影像格式转换、波段合并
Rasterio
简化G ...
引言高程数据(Elevation Data)是地理空间分析的核心数据类型,融合了矢量(点/线/面)和栅格(像素网格)的特性,其三维属性(X/Y平面坐标+Z高程值)在地形可视化、水文建模、地貌分类和路径规划等领域具有不可替代的作用。《Learning Geospatial Analysis with Python》(第八章“Python and Elevation Data”)系统梳理了高程数据的处理流程,从点云到栅格DEM,再到三维建模,为开发者提供了全面的技术指南。
本文通过详细的代码示例和实际案例,深入解析高程数据的核心处理技术,包括LiDAR点云处理、DEM坡度分析、三维地形建模和洪水模拟。我们还将探讨性能优化(如分块处理和并行计算)、AI辅助开发以及未来趋势,帮助开发者构建高效、可靠的高程数据分析工作流。
一、高程数据的四大类型与处理工具高程数据涵盖多种格式,每种格式适用于特定场景。以下是主要类型及其处理工具:
1. 数据格式与特点
格式
数据类型
典型应用
Python处理库
DEM
栅格
地形渲染、坡度/坡向计算
GDAL, Rasterio, NumPy
...
第一章:学习使用 Python 进行地理空间分析本章概述了地理空间分析。我们将通过一个案例研究,探讨地理空间技术如何影响我们的世界,案例涉及历史上最严重的疫情之一,以及地理空间分析如何帮助追踪疾病传播,为研究人员争取时间开发疫苗。接下来,我们将回顾地理空间分析的历史,这一历史甚至早于计算机和纸质地图!然后,我们将探讨为什么作为地理空间分析师,你可能需要学习编程语言,而不是仅仅使用地理信息系统(GIS)应用程序。我们将认识到让尽可能多的人接触地理空间分析的重要性。接着,我们将介绍基本的 GIS 和遥感概念及术语,这些内容将贯穿本书始终。最后,我们将通过从零开始构建一个最简单的 GIS,正式开始使用 Python 进行地理空间分析!
本章涵盖的主题快速概览如下:
地理空间分析与我们的世界
地理空间分析的历史
地理信息系统(GIS)的演变
遥感概念
点云数据
计算机辅助制图
地理空间分析与计算机编程
地理空间分析的重要性
GIS 概念
常见的 GIS 过程
常见的遥感过程
常见的栅格数据概念
创建最简单的 Python GIS
通过本章的学习,你将理解地理空间分析作为一种解答我们世界问 ...
在日常的开发和运维工作中,我们经常需要程序在完成特定任务(例如数据处理、备份、定时脚本执行等)后,自动发送邮件通知相关人员。这不仅能让我们及时了解任务状态,还能在出现问题时迅速响应。本文将介绍如何使用 Python 的 smtplib 和 email 模块来实现邮件发送功能,并特别说明如何将其嵌入到应用中,例如在数据处理完成后发送通知。
为什么选择 Python 发送邮件?
自动化流程:当一个耗时的脚本(如数据分析、模型训练)执行完毕后,自动发送邮件通知可以省去人工检查的麻烦。
集成性好:Python 作为一门“胶水语言”,可以方便地集成到现有的应用或脚本中。
标准库支持:Python 内置了 smtplib 和 email 模块,无需安装额外的第三方库即可实现核心功能。
准备工作
Python 环境:确保你的系统中已安装 Python。
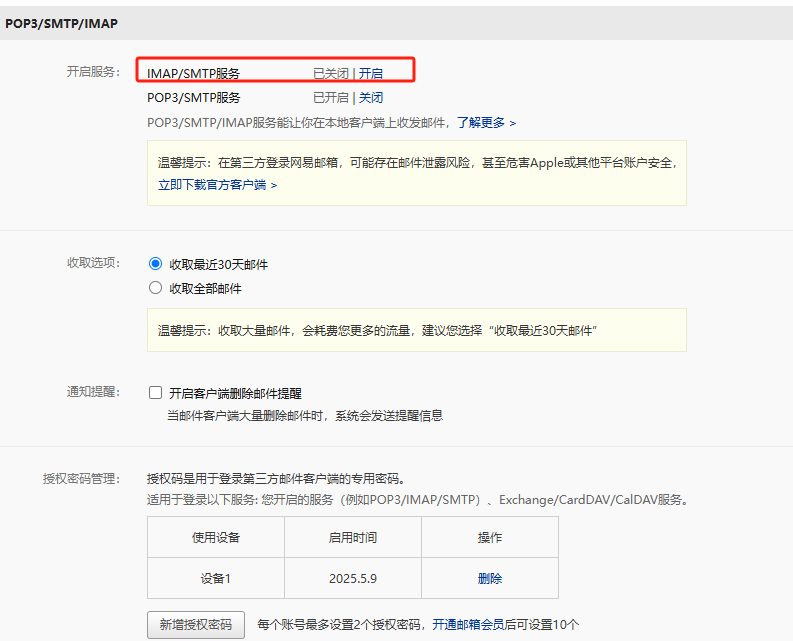
开启邮箱的 SMTP 服务并获取授权码:
你需要在你的邮箱服务提供商(如 QQ 邮箱、163 邮箱、Gmail 等)的设置中开启 SMTP 服务。
重要:大多数邮箱服务商出于安全考虑,不再允许直接使用邮箱密码通过 SMTP 发送邮件,而是需要生 ...

python
未读编程语言就像工具箱里的工具:有些被频繁使用,有些却被尘封在角落。几十年前,这些语言曾是程序员的宠儿,如今却大多淡出了人们的视线。让我们一起探索10种曾经辉煌、如今却鲜为人知的古老编程语言,感受编程历史中的独特魅力!
1. ALGOL
诞生时间:20世纪50年代末特点:ALGOL,全称“算法语言”(Algorithmic Language),是为清晰表达算法而设计的。它引入了“begin”和“end”代码块的写法,影响了C和Java等现代语言。兴衰:ALGOL在60年代风靡一时,但因过于复杂,70年代逐渐被更简单的语言取代。它是编程语言的先驱,奠定了许多现代语言的基础。代码示例:
begin
integer x;
x := 5;
print(x)
end
2. COBOL
诞生时间:1959年特点:COBOL(Common Business-Oriented Language)专为商业数据处理设计,代码冗长但易读,类似英语。兴衰:它曾是60-70年代银行和保险行业的支柱,但因运行缓慢、体积庞大,如今多见于老式大型机。传闻一些银行仍在使用它!代码示例:
IDENTIFICA ...
python
未读欢迎体验 NumPy 的强大功能!NumPy 是 Python 中用于科学计算的核心库,特别适合处理多维数组和矩阵运算。本教程将带你快速上手 NumPy,面向零基础或初学者,涵盖数组创建、操作、索引等核心概念。
先决条件在开始之前,你需要:
基础 Python 知识:了解列表、元组、循环等基本概念。如需复习,可参考 Python 官方教程。
安装 NumPy:通过 pip install numpy 安装 NumPy。
安装 Matplotlib(可选):部分示例(如直方图)需要 Matplotlib,可通过 pip install matplotlib 安装。
注意:本教程假设你已安装 Python 环境并能运行代码。如果你是新手,推荐使用 Jupyter Notebook 或 VS Code 来运行代码,方便交互式学习。
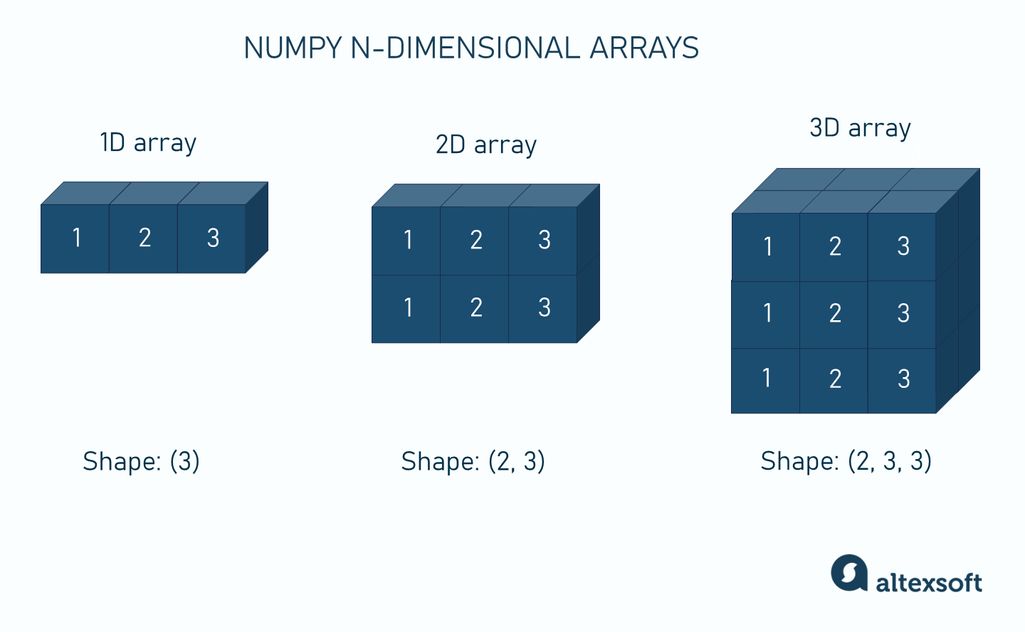
学习者概况本教程是 NumPy 数组的入门指南,重点讲解如何表示和操作 n 维数组(ndarray)。如果你:
不清楚如何对 n 维数组应用常见函数(无需 for 循环);
想了解数组的 轴(axis) 和 形状(shape) 属性;
希望快速掌握 ...
自Python 3.6引入F-String(格式化字符串字面量)以来,它以简洁、高效和易读的特性成为字符串格式化的首选,完胜传统的.format()和%方法。F-String不仅能插入变量,还有许多强大功能!本文将介绍5个实用F-String技巧,助你编写更优雅、更高效的Python代码,特别贴合中文开发场景。快来一起解锁F-String的潜力吧!
1. 直接计算表达式,代码更简洁F-String支持在{}内直接运行Python表达式,无需提前定义临时变量。无论是数学运算、字符串操作还是函数调用,都能一步完成。
示例:
name = "小明"
age = 25
# 传统方式
print("{}明年将是{}岁。".format(name, age + 1))
# F-String方式
print(f"{name}明年将是{age + 1}岁。")
输出:
小明明年将是26岁。
优势:
省去中间变量,代码更紧凑。
逻辑直观,适合快速开发和团队协作。
2. 数字格式化,轻松应对多种场景F-String让数字格式化变得简单,支持保留小数、添加千位分隔符和百分比显示,完美适配报表和数 ...
python
未读自 Python 2.7 发布以来,Python 语言已经发生了翻天覆地的变化。如果你还在用十多年前的方式编写 Python 代码,那么你可能错过了许多现代 Python 提供的强大功能、简洁语法和最佳实践。在这篇博客中,我们将探讨如何让你的 Python 项目现代化,采用符合 2025 年标准的最佳实践,编写更高效、更优雅的代码。
1. 使用 f 字符串进行字符串格式化在 Python 的早期,字符串格式化主要依赖 % 运算符或 .format() 方法。然而,从 Python 3.6 开始,f 字符串(格式化字符串字面量)成为了更推荐的选择。它们不仅更易读,还在性能上更优。
传统方式
name = "小明"
age = 25
print("我的名字是 %s,今年 %d 岁。" % (name, age))
print("我的名字是 {},今年 {} 岁。".format(name, age))
现代方式(f 字符串)
name = "小明"
age = 25
print(f"我的名字是 {name},今年 {age} 岁。")
f 字符串语法简洁、直观,支持任意 Python 表达 ...

python
未读Windows 10上最简单的GDAL安装指南:小白学遥感的起点对于遥感初学者来说,GDAL(Geospatial Data Abstraction Library)是一个绕不开的核心工具。它可以处理各种地理空间数据格式,是遥感、GIS分析的基石。然而,GDAL的安装过程常常让新手望而却步:网上的教程要么过时,要么充斥着复杂的术语和步骤。本文将以最简单的方式,带你一步步在Windows 10上安装GDAL,适合零基础的小白。
为什么选择.whl文件安装?GDAL的官方安装方式需要编译源码,或者依赖复杂的环境配置,对于初学者来说费时费力。最快、最简单的方法是通过Python的pip工具,结合预编译的.whl(wheel)文件安装。.whl文件是Python的二进制包,省去了编译的麻烦,直接安装即可。
我们推荐从Christoph Gohlke维护的geospatial-wheels下载GDAL的.whl文件。这个仓库提供了针对Windows的预编译GDAL包,兼容性好,更新及时。
下载地址是:https://github.com/cgohlke/geospatial-wheels/re ...

在 Python 中,if 语句、break、continue 和 pass 是控制流的关键工具,用于控制程序的执行逻辑。以下是它们的含义和使用方式的简洁解释:
1. if 语句
含义: 用于条件判断,根据条件(True 或 False)决定执行哪部分代码。
用法:
if 条件:
# 条件为 True 时执行
elif 其他条件:
# 其他条件为 True 时执行
else:
# 条件为 False 时执行
理解: 就像生活中的“如果……就……”,比如“如果下雨,就带伞”。
示例:
x = 10
if x > 5:
print("x 大于 5") # 输出: x 大于 5
else:
print("x 小于或等于 5")
2. break
含义: 立即退出当前的循环(for 或 while),不再执行循环的剩余部分。
用法: 常用于循环中,当满足某个条件时提前终止循环。
理解: 像在超市找东西,找到目标后就立刻离开,不再逛其他货架。
示例:for i in range(10):
if i == 5:
...

