深度学习
未读1、详细介绍技术背景,并描述已有的与本发明最相近似的实现方案
1.1 技术背景1.2 最相近似的现有实现方案
2、现有技术的缺点是什么?针对这些缺点,说明本发明的目的。(客观评价,现有技术的缺点是针对于本发明的优点来说的,本发明不能解决的缺点不必写;基于本发明能解决的问题写出发明的目的)
2.1 现有技术的缺点
2.2 本发明的目的
3、本发明技术方案的详细阐述,应该结合示意图进行说明(越详细越好,至少要提供2页;发明中每一功能的实现都要有相应的技术实现方案;所有英文缩写都应有中文注释;所有附图都应该有详细的文字描述,以别人不看附图即可明白技术方案为准;同时附图中的关键词或方框图中的注释都尽量用中文;方法专利都应该提供流程图,并提供相关的系统装置图;工艺专利都应提供整个工艺的流程图,附图中各相关部件都要提供名称)。
附图说明
下面结合附图和实施例对本专利进一步说明。
4、本发明的关键点和欲保护点是什么?(发明内容部分提供的是为完成一定功能的完整技术方案,在本部分是提炼出技术方案的关键创新点,列出1、2、3…,以提醒代理人注意,便于代理人撰写权利要求书)
5、与第1部分最好的现有技术相比 ...

深度学习
未读当水货13年了。。。 大学四年没谈过恋爱,全献给了游戏。谈恋爱哪里有开黑爽?至于学习,低分飘过不挂科就是胜利。当时的信念是,好不容易考上大学,以后注定是去工地的,不如趁着年轻多打一会游戏!
直到大三去野外实习,扛着全站仪在烈日下走了一周,看着磨破的脚底板和黑了三度的脸,我悟了:做测绘太累了,要不考研?
吭哧吭哧的翻开高数书从头开始学习微积分,英语单词从abandon开始背起来。
我那时候水到什么程度?直到开考前三个月,我才知道考研得先报学校再考试。仓促之下,为了求稳直接报了本校。没成想,这种“盲人骑瞎马”的搞法居然让我上岸了,继续在母校混了三年硕士。
工作第一年家里攒了为数不多的口罩,全给我塞进了大包。我就这样背着沉重的行囊,像个孤勇者一样杀到了广州。 入职第一天,组长丢给我一堆高分二号(GF-2)的原始数据。
“去,把这些图做了。” 我盯着屏幕发呆:什么是ENVI处理高分影像? 在学校我只会在 Google Earth Engine (GEE) 里写两行 JavaScript 调现成的层,那种“点一下运行就出图”的快感让我产生了“我遥感很强”的错觉。
面对本地处理软件,我连大气校正 ...
啥是波段顺序?想象一下,一张遥感图像不是普通的照片,它有好多“层”——这些层叫“波段”(bands)。每个波段捕捉不同颜色的光,比如:
R(Red):红色波段,帮你看植物的健康(因为健康的植物反射红光少)。
G(Green):绿色波段,看植被覆盖。
B(Blue):蓝色波段,帮分析水体或大气。
在电脑里,这些波段像三明治一样叠起来。最常见的有两种顺序:
RGB:红-绿-蓝(这是我们眼睛看照片的自然顺序,很多图片软件默认这个)。
BGR:蓝-绿-红(这是OpenCV这个流行库的习惯,因为历史原因)。
深度学习模型(比如用PyTorch或TensorFlow建的神经网络)在“学习”的时候,会记住这些层的顺序。比如,它会想:“第一层是蓝的特征,第二层是绿的……” 如果你训练时用BGR,但预测(就是用模型猜新图片)时喂它RGB,模型就懵了!它会把蓝当成红,绿当成蓝,结果当然乱七八糟,就像你把鞋子左右穿反了,走路肯定歪歪扭扭。
为啥训练和预测要一致?模型的“记忆”:模型不是随便猜的,它在训练时学的是特定顺序的图案。如果你换顺序,就等于给它看颠倒的地图——它能认出来才怪!
遥感数据的特殊性 ...

大家好,我是小白。很久没写公众号了。
今天聊一聊什么是遥感影像样本库及制作流程。
开门见山地说,深度学习需要的样本,我的理解是:指导计算机去识别、理解输入内容。。
主语是计算机,动词是 识别, 对象是 输入内容。
样本一般形式是 两两为一对 出现。
一、样本的基本组成
Image(原始影像)
就是我们的输入素材,遥感里一般是卫星 / 航拍 / 无人机拍摄的影像,格式多为 TIFF/GeoTIFF(带地理坐标),也可转 JPG/PNG。 我一般是滑窗分割为小瓦片转为png,大小一般是512x512。
Label(标注 / 标准答案)
是给计算机看的「正确答案」,文件格式主要分两类:
图片格式(掩码图)
文本格式(坐标 + 类别)
在语义分割,样本一般是图片+图片的形式。
在目标识别,样本一般是图片+文本的形式。
在语义分割也分为二分类和多分类。
二、不同任务的样本配对(遥感最常用)语义分割(像素级分类,如土地利用分类、水体提取)
形式:影像图 + 标注图(图片格式)
每个像素都对应一个类别,逐像素匹配。
目标检测(找位置 + 类别,如找建筑、车辆、桥梁、光伏板)
形式:影像图 ...
大家好,我是小白。今天分享一个轻量化脚本,只需配置路径和少量参数,就能基于 TIFF 影像 + SHP 矢量自动生成 YOLO-Seg 格式的分割样本,还能自动划分训练 / 验证集、生成标准 data.yaml 配置文件,开箱即用!
当然,前提是,要提前绘制好矢量。绘制矢量这个步骤很麻烦,费时费力,不在这里细说。
核心思路整个流程无需复杂操作,核心就 4 步:
矢量栅格化:将 SHP 矢量转为与 TIFF 影像尺寸、投影完全匹配的二值掩膜(有目标的区域为 255,背景为 0);
滑窗分块:对大尺寸 TIFF 和掩膜按指定尺寸滑窗分块,支持重叠率设置;
标签生成:从掩膜中提取目标轮廓,归一化后生成 YOLO-Seg 格式标签(自动过滤小面积无效轮廓);
数据集整理:随机划分训练 / 验证集,生成 YOLO 训练所需的 data.yaml 文件。
快速使用1. 配置参数只需修改代码末尾的 4 个核心路径 / 参数:
TIFF_PATH = r"你的大尺寸TIFF影像路径"
SHP_PATH = r"对应的SHP矢量文件路径"
OUTPUT_DIR = r"样本输出目录"
temp_ma ...
python
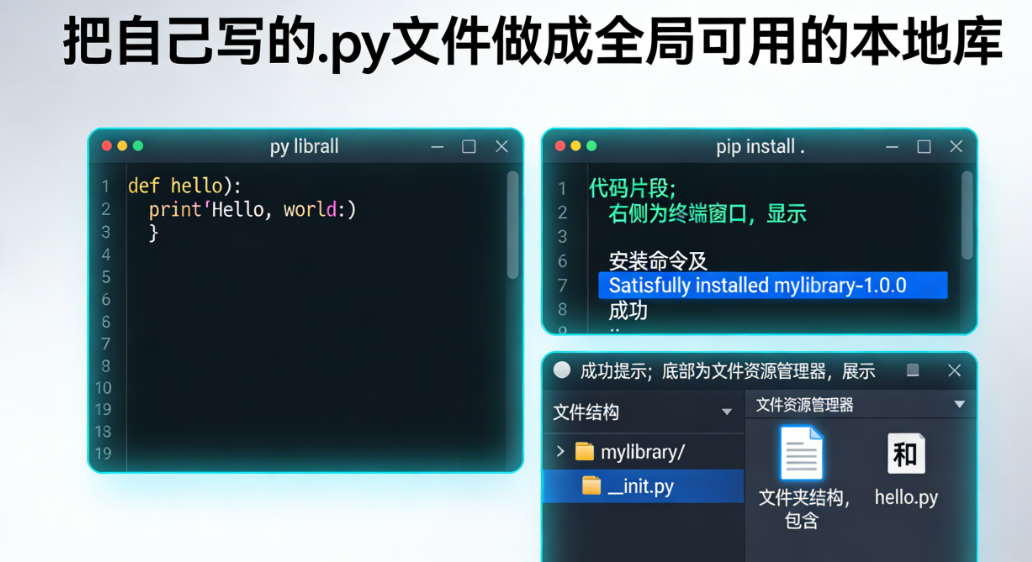
未读大家好,我是小白。今天这篇文章就来讲一讲如何把自己写的.py 文件做成全局可用的本地库。
一、核心原理:Python 模块搜索机制在开始之前,先了解下 Python 的模块搜索规则:当你执行import module_name时,Python 会按以下顺序查找模块:
内置模块(如sys、os等)
sys.path列表中的目录(包括当前脚本目录、PYTHONPATH 环境变量指定目录、Python 安装目录下的 site-packages 等)
如果找不到,就会抛出ModuleNotFoundError
我们的目标就是把自己的模块所在路径添加到 Python 的搜索路径中,或者直接放到它本来就会搜索的目录里。
二、方案一:简单粗暴 —— 直接放入 site-packages(适合快速测试)这是最直接的方法,适合临时测试或简单脚本的复用,原理就是把你的模块放到 Python 默认的第三方库目录里。
操作步骤:
找到 site-packages 目录
import numpy # 任意第三方库均可
print(numpy.__file__)
输出类似C:\Users\用户名\App ...

大家好,我是小白。OPENCV是一个实用的库,很多传统的算法都可以通过它进行调用。
今天这篇文章就来讲一讲OpenCV Python ,顺便把 OpenCV Python 绑定的历史、包的区别、常见错误原因、推荐安装方式全部说透。
一、OpenCV 简介与 Python 绑定的历史OpenCV(Open Source Computer Vision Library)是一个由 Intel 在 1999 年发起的开源计算机视觉库,现在由 OpenCV.org 基金会维护。目前最新稳定版是 OpenCV 4.12.x。
OpenCV 最开始是用 C++ 写的,后来提供了 Python 绑定,让 Python 开发者也能轻松使用。
关键历史节点:
OpenCV 1.x 时代(2000-2008):Python 绑定模块名叫 cv,导入方式是 import cv。那个时候的接口比较原始,函数名也比较长。
OpenCV 2.0(2009 年):大重构!C++ 接口全面现代化,Python 绑定也彻底重写。新绑定的模块名定为 cv2,导入方式变成 import cv2(或 from cv2 im ...
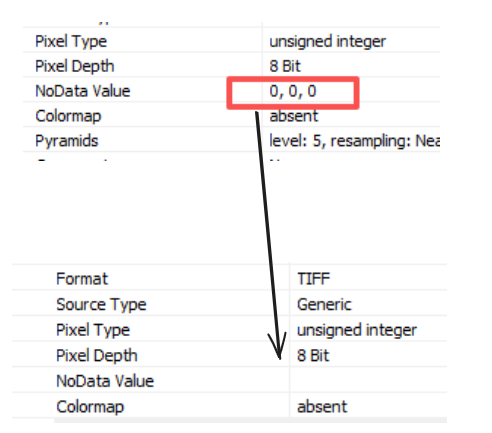
GDAL(Geospatial Data Abstraction Library)是一个开源的地理空间数据转换库,常用于处理栅格(Raster)和矢量(Vector)数据。在栅格影像处理中,NoData 值用于表示无效或缺失的数据区域(如背景或无效像素)。有时,我们需要移除这些 NoData 值,以适应特定的数据分析或可视化需求。
下面是具体代码:
from osgeo import gdal
import sys
def remove_nodata(out_path):
# 以可写模式打开输出影像
out_ds = gdal.Open(out_path, gdal.GA_Update)
if out_ds is None:
raise Exception(f"无法以可写模式打开输出影像:{out_path}")
# 检查 GDAL 版本(可选,推荐 >= 3.1 以支持 DeleteNoDataValue)
print("GDAL 版本:", gdal.__version__)
su ...

我其实会的技能是很杂的,BOSS直聘是我一直保存手机的app,时不时看看不同的岗位的需求是什么。是的,我有一颗想跳槽的心,这也是我会的技能是很杂的原因。正如我从测量工作跳槽到遥感领域工作一样,至今我还记得怎么快速摆正三脚架。
今天我又看了下boss直聘的岗位,我一般不止是看遥感相关的,我还会看其他岗位。因为我是想跳槽的,跳槽到别的行业。
做遥感只是在吃老本。不过好在2025年,我大半年的时间都是在做深度学习和遥感结合的工作,我不在这里写过多与现工作相关的内容。这里只记录我在业余时的学习记录。
在业余时间,我依然会写一写公众号,并且在2026年我会选择一项技能点 好好学习,可能是三维重建,可能是嵌入式,至于具体深入学到什么程度,现在我还没想好。
现在我的现状很尴尬,这里会一些,那里会一些。这导致了我认为自己是学艺不精。小时候就听说过:学海无涯苦作舟。实际上我每天都在接触新的东西,真的是学不完。学不完也是指我的心太野了。
2025年,我写了两三个发明专利,其实也发明专利比写论文要简单太大。只要你有思路,只要你的思路能用代码实现,加上你的思路有创新,那么这样的思路就能变成发明专利。2026 ...

