1.选取GPS连续运行参考站时,视场内障碍物的高度角一般不超过( )。A.5° B.10° C.15° D.20°答案: B
2.某GPS网同步观测一个时段,共得到6条基线边,则使用的GPS接收机台数为( )台。A.3 B.4 C.5 D.6答案: B
3.某地区最大冻土深度1.2米,埋设B级GPS点土层天线墩需要挖坑深度为( )m。A.1.7 B.1.8 C.1.9 D.2.0答案: C
0.073.0.074.0.076m,此时,对天线高的正确处理方法是( )。A.取中数0.0743m作为天线高 B.取中数0.074m作为天线高 C.重新选择三个位置量取天线高 D.重新整平仪器量取天线高答案: D
6.一晴朗夏日,某一等水准测量,在北京地区观测,测段进行一半时,已经接近上午十点,此时,观测组应( )。A.继续观测 B.打伞观测 C.打间歇 D.到下一水准点结束观测答案: C
7.采用数字水准仪进行二等水准观测,仪器设置完成后,起测的第一站前后视距分别为50m.48m,后尺读数为1.54288m,前尺读数为0.54288m,仪器显示超限。其原因是( )超限。A.视线长度 B.前后视距 ...
1.使用N台(N>3)GPS接收机进行同步观测所获得的GPS边中,独立的GPS边的数量是( )。A.N B.N-1 C.N(N+1)/2 D.N(N-1)/2答案: B
2.我国现行的大地原点.水准原点分别位于( )。A.北京.浙江坎门 B.北京.山东青岛 C.山西泾阳.浙江坎门 D.陕西泾阳.山东青岛答案: D
3.大地水准面精化工作中,A.B级GPS观测应采用( )定位模式。 A.静态相对 B.快速静态相对 C.准动态相对 D.绝对答案: A
4.为求定GPS点在某一参考坐标系中的坐标,应与该参考坐标系中的原有控制点联测,联测的点数不得少于( )个点。A.1 B.2 C.3 D.4答案: C
5.地面上任意一点的正常高为该点沿( )的距离。A.垂线至似大地水准面 B.法线至似大地水准面 C.垂线至大地水准面 D.法线至大地水准面答案: A
6.GPS的大地高H.正常高h和高程异常ζ三者之间正确的关系是( )。A.ζ=H-h B.ζ<H-h C.ζ=h-H D.ζ<h-H答案: A
7.按现行《全球定位系统(GPS)测量规范》,随GPS接收机配备的商用软件只能用于( )。A.C级及以 ...
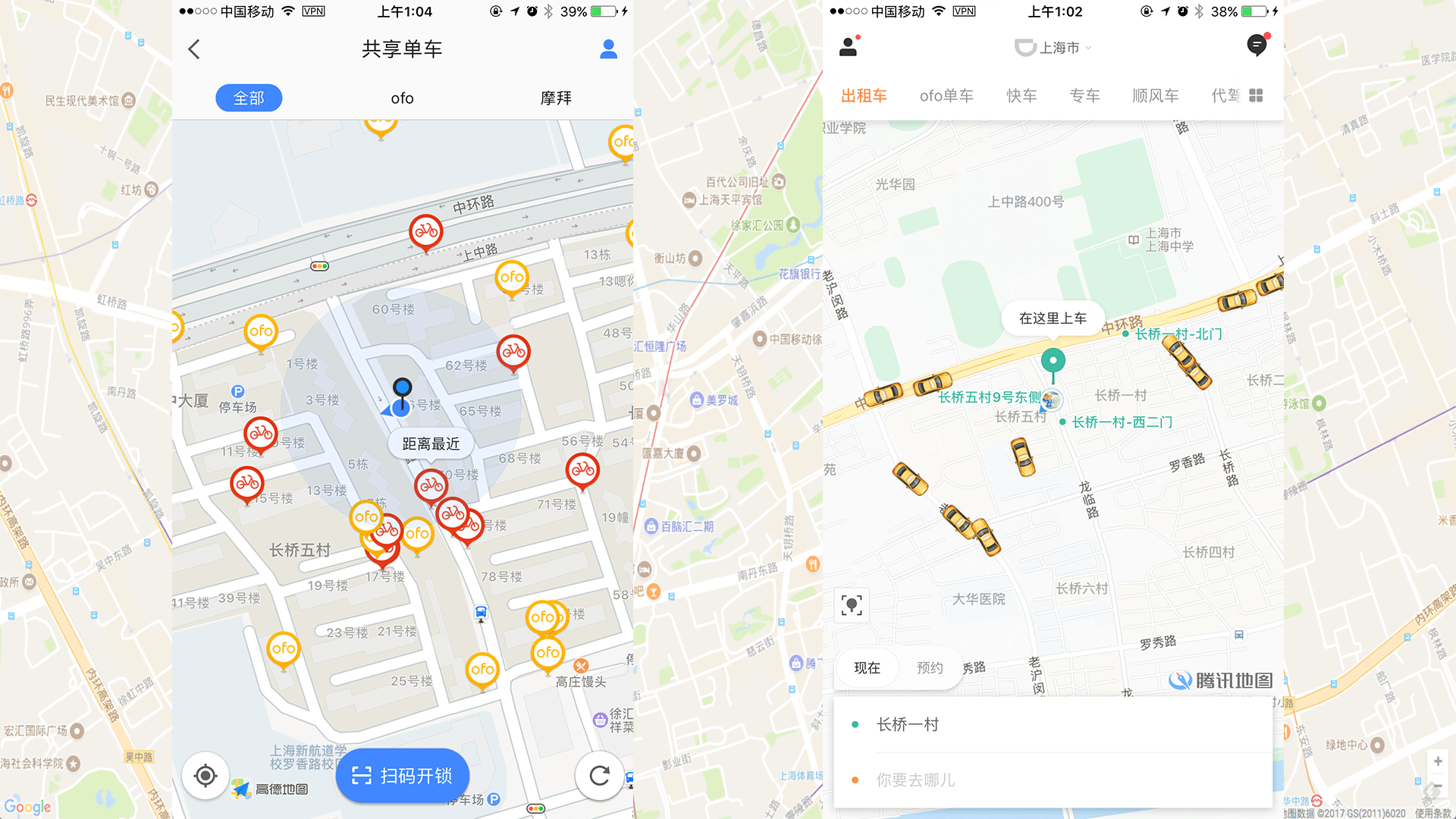
每天我们晚上加班回家,可能都会用到滴滴或者共享单车。打开 app 会看到如下的界面:
app 界面上会显示出自己附近一个范围内可用的出租车或者共享单车。假设地图上会显示以自己为圆心,5公里为半径,这个范围内的车。如何实现呢?最直观的想法就是去数据库里面查表,计算并查询车距离用户小于等于5公里的,筛选出来,把数据返回给客户端。
这种做法比较笨,一般也不会这么做。为什么呢?因为这种做法需要对整个表里面的每一项都计算一次相对距离。太耗时了。既然数据量太大,我们就需要分而治之。那么就会想到把地图分块。这样即使每一块里面的每条数据都计算一次相对距离,也比之前全表都计算一次要快很多。
问题就来了,地图上的点是二维的,有经度和纬度,这如何索引呢?如果只针对其中的一个维度,经度或者纬度进行搜索,那搜出来一遍以后还要进行二次搜索。那要是更高维度呢?三维。可能有人会说可以设置维度的优先级,比如拼接一个联合键,那在三维空间中,x,y,z 谁的优先级高呢?设置优先级好像并不是很合理。
本篇文章就来介绍1种比较通用的空间点索引算法——GeoHash 。
在最基本的层面上,GeoHash 将二维地理坐标编码成字 ...

之前实现了对注册测绘师综合真题PDF转换为文本数据。但是这些文本数据,不能直接导入到数据库中的。
而本文针对这个问题,进行展开。最终实现注册测绘师真题文本处理与答案高亮。
数据结构首先理清楚数据结构。比如以下这3道题:
1.使用N台(N>3)GPS接收机进行同步观测所获得的GPS边中,独立的GPS边的数量是
( )。
A、N B、N-1 C、N(N+1)/2 D、N(N-1)/2
答案:B
2.我国现行的大地原点、水准原点分别位于( )。
A、北京、浙江坎门 B、北京、山东青岛 C、山西泾阳、浙江坎门 D、陕西泾阳、山东青岛
答案:D
3.大地水准面精化工作中,A、B级GPS观测应采用( )定位模式。
A、静态相对 B、快速静态相对 C、准动态相对 D、绝对
答案:A
需要把以上的文本分为
1.题目
2.选项
3.答案
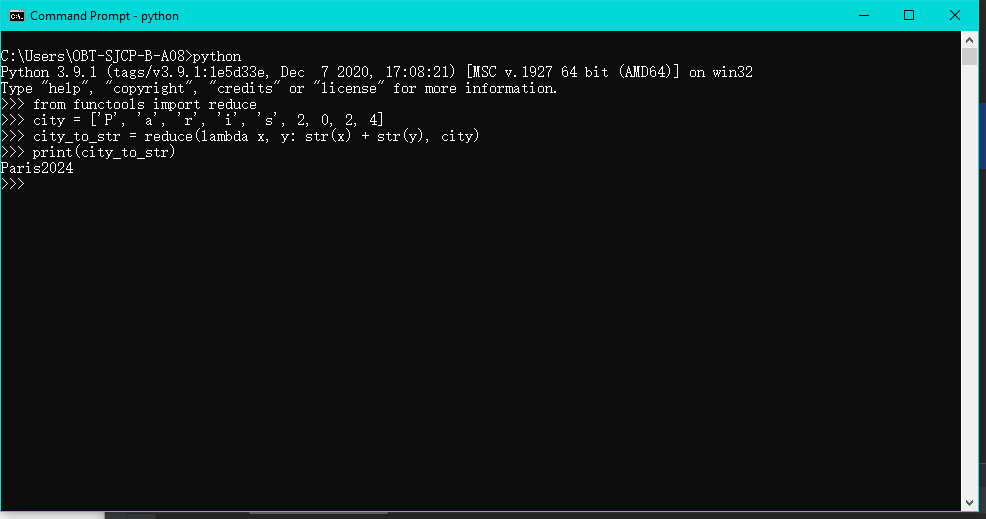
对于文字的处理,我们通常用到正则式re。re是一个非常强大的库,它又简单又困难。简单是指它容易使用;困难是指如果要实现指定功能,它就变得很困难。
反正通过re,我们可以实现以上需求。
def parse_text(text):
'''
用于201 ...
这篇文章介绍了9个Python技巧,帮助编写更优雅的Python代码。
Pythonic 是优雅的同义词Python之禅最早由 Tim Peters在Python邮件列表中发表,它包含了影响[Python编程语言设计的19条软件编写原则。
Python之禅的内容:
优美优于丑陋,
明了优于隐晦;
简单优于复杂,
复杂优于繁杂,
扁平优于嵌套,
稀疏优于稠密,
可读性很重要!
特例亦不可违背原则,
即使实用比纯粹更优。
错误绝不能悄悄忽略,
除非它明确需要如此。
面对不确定性,
拒绝妄加猜测。
任何问题应有一种,
且最好只有一种,
显而易见的解决方法。
尽管这方法一开始并非如此直观,
除非你是荷兰人。
做优于不做,
然而不假思索还不如不做。
很难解释的,必然是坏方法。
很好解释的,可能是好方法。
命名空间是个绝妙的主意,
我们应好好利用它。
优美优于丑陋,这不仅是《Python 禅》的第一句话,也是所有 Python 开发者的信条。
但如何区分代码的美丑呢?更重要的是,如何编写漂亮的 Python 代码?
空谈误国。将以初学者易懂的示例演示 ...
今天读到了一个行业前辈在他博客写文章:基于Google影像的大数据几何校正思考
基于这篇文章,写一写我的思考。
前辈的文章以下是前辈文章的内容:
前一段时间一直在闲暇的时候做着无人机影像处理方面的工作,也算是小有建树了。前两天突然有了一个思考,那就是关于如何更快速的进行校正处理,实际上我们处理的图片,或者说我们处理的影像在很多情况下只需要有一个准确的相对位置关系而并不是需要绝对精度有多么的高,因为理论上影像绝对精度不可能高于影像分辨率,因为控制点的选取本身对于影像来说从影像上选取像控点就存在误差,而亚像元精度的像控点选取通过测量控制点的方式几乎是无法做到的,鉴于此种情况,我认为影像的校正处理还是应该集中在相对位置的校正上,而绝对未知跟具体的影像质量硬件技术有关。实际上在地图应用的过程中能够与底图叠合我们认为就是比较精确的了,那么我们是不是可以利用Google Map提供的瓦片数据自动的选取控制点进行校正。对于以上采用Google Map瓦片数据进行校正我认为主要有两个优势:
1.Google Map在全球的数据能够完美的拼接,且作为地图标准的底图都是以它为标准
2.数据获取免费且方 ...

之前介绍如何通过pdfplumber获取PDF的文本。
基于上次所写的内容,继续深挖。现在使用Python从PDF中提取文本并转换为Markdown的实际操作。
背景现在有12个注册测绘师综合真题的PDF,但是里面很多广告,个人希望把这些广告消除了。如果是少量pdf,那么用WPS然后花钱开会员的应该能把广告清理掉。但是这12个PDF对应着12年的注册测绘师综合真题,每个PDF有100页,一页一道真题。如果手动清理广告,这个工作量是很大的。
先把PDF转为文本,然后对这些文本进行数据清理,这个是对单个PDF的转纯净文本的思路。
思路这个编程思路,也是我平常写代码去解决问题的思路。
先解决简单的问题,提取共性,再解决复杂的问题,在这过程中把握好输入输出。
这句话有很多种角度去理解。
就具体事情来说,先解决单个PDF格式转换文本,再进行数据清洗。进而解决批量PDF格式转换文本且数据清洗。
单个PDF格式转换文本相关实现代码如下:
def read_pdf(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
...
categories: [编程,python]
函数名
函数名
函数名
函数名
函数名
abs
aiter
all
any
ascii
bin
bool
bytearray
bytes
callable
chr
classmethod
compile
complex
delattr
dict
dir
divmod
enumerate
eval
exec
exit
filter
float
format
getattr
globals
hasattr
hash
help
hex
id
input
int
isinstance
issubclass
iter
next
len
list
locals
map
max
min
oct
open
ord
pow
print
property
quit
range
repr
reversed
round
set
sorted
str
sum
tuple
type
zip
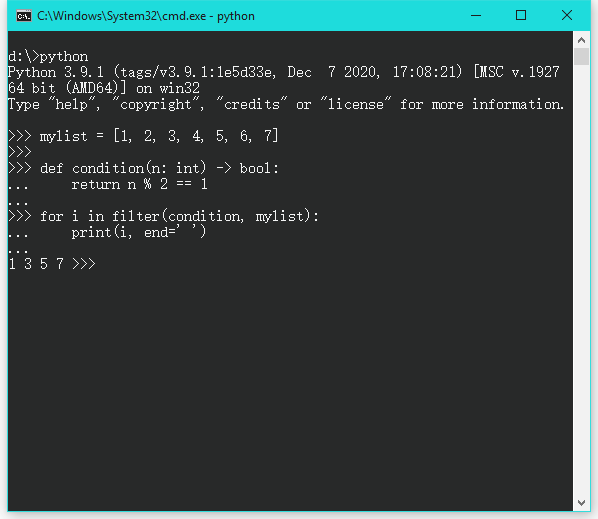
abs()负数变为正数。正数仍然是正数。
print(abs(-10)) # 10 ...
https://readmedium.com/zh/yolo-intuitively-and-exhaustively-explained-83143925c7a9

