
深度学习
未读朋友们,你觉得一张10672 × 9525像素的 RGB 图像(3 个颜色通道)是多大?
我最近我使用小白影像下载器,下载了一张影像。我一看这个文件大小,把我看惊了。
它的大小高达 8.95兆。
这确实是非常高效的压缩。今天我们探讨一下关于谷歌地球如何实现如此高效压缩的分析,以及这背后可能的压缩技术和步骤。
1. 计算未压缩图片大小首先,计算未压缩的图片大小以了解压缩程度:
像素总数:10672 × 9525 = 101,660,700 像素
每像素字节数:RGB 图像,3 通道 × 8 位(1 字节)= 3 字节/像素
总字节数:101,660,700 像素 × 3 字节/像素 = 304,982,100 字节
转换为 MB:1 MB = 1,048,576 字节
304,982,100 ÷ 1,048,576 ≈ 290.91 MB
相比之下,谷歌地球将这张图片压缩到 8.95 MB,压缩比约为 290.91 ÷ 8.95 ≈ 32.5:1,显示出极高的压缩效率。
2. 谷歌地球影像压缩的实现方式谷歌地球(Google Earth)使用卫星或航空影像,通过以下技术和策略 ...
在 Ascend 生态中,CANN(Compute Architecture for Neural Networks)工具包涉及的 固件(Firmware) 和 驱动(Driver) 是支持 Ascend NPU(Neural Processing Unit)硬件运行的两个关键组件。它们与 CANN toolkit(开发套件)共同构成完整的 NPU 开发和运行环境。以下是它们的定义、作用和区别,结合你在 ARM Linux 上安装 torch-npu 的目标,简洁说明:
1. 固件(Firmware)
定义:固件是运行在 Ascend NPU 硬件上的低级软件,直接控制 NPU 芯片的硬件行为(如计算单元、内存管理)。它是芯片的嵌入式程序,类似 BIOS 或嵌入式设备的微代码。
作用:
初始化和管理 NPU 硬件。
提供硬件层接口,处理任务调度、数据传输等。
确保 NPU 芯片能正确执行计算任务。
安装特点:
文件名如 Ascend-ascend910-firmware_xxx_linux-aarch64.run。
需 root 权限 安装,因为涉及直接写入硬件寄存器或设备固件区域 ...
写博客是一种低成本但高价值的记录方式,主要投入的是时间,而非金钱。
以我为例,我仅花费200元购买了十年的域名,平均每年成本微乎其微。如果你想进一步省钱,甚至可以完全不购买域名,利用免费平台照样能搭建博客。
我的博客使用的是静态网站,托管在GitHub Pages上,基于开源的Hexo框架。
这意味着整个搭建过程几乎没有额外费用,只需花时间学习和配置即可。对于想开始写博客的人,搜索Hexo教程是一个简单直接的起点,网上有大量免费资源和指南,足够帮助你快速上手。
静态网页的定义,简单来说,就是内容在生成后不会因用户请求而动态变化。
换句话说,访问者看到的内容是固定的,不会因为用户的操作而实时生成或修改。
以我之前开发的小程序为例,它也是静态网页的一种,内容事先准备好,加载后直接呈现。
相比动态网页,静态网页的开发和维护成本低得多,因为它不需要复杂的后端支持,比如用户登录系统、数据库管理或实时数据处理。
这对个人博客来说尤其适合,因为大多数博客的核心功能是展示内容,而非交互。
选择静态网页的好处还在于它的轻量和高效。
托管在GitHub Pages这样的平台上,不仅免费,还能借助版本控 ...
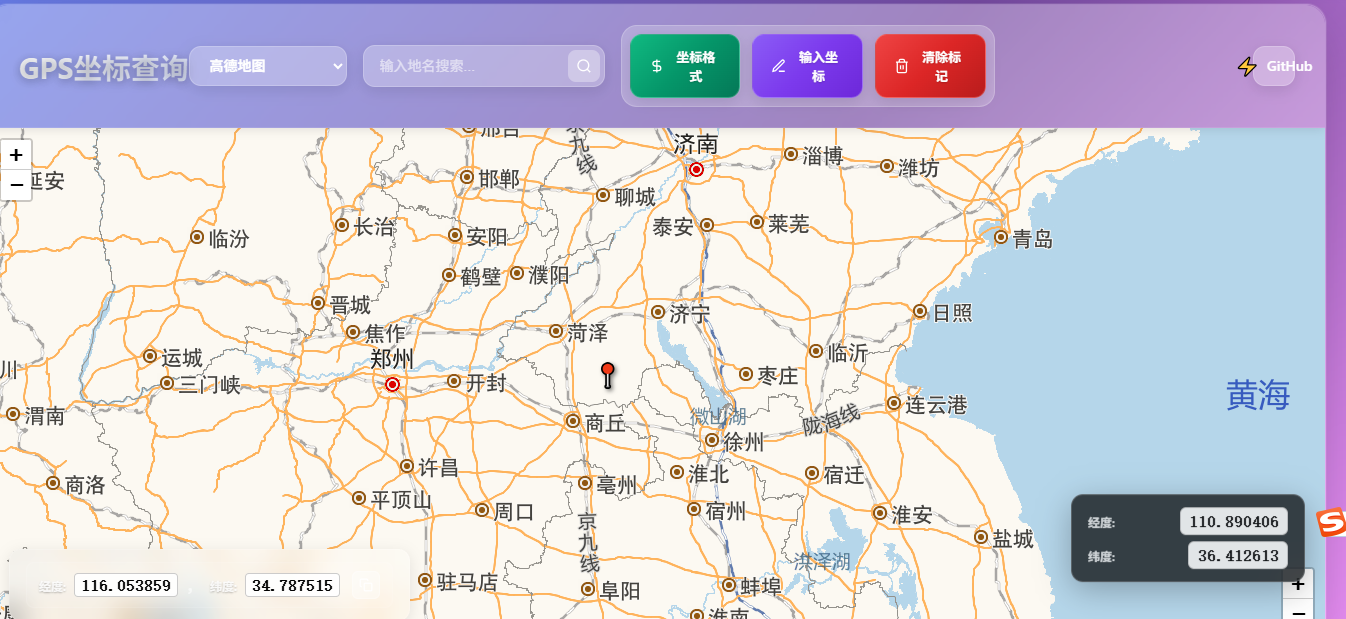
打造一个简洁实用的经纬度查询工具最近折腾了一个基于Web的经纬度查询工具,挺有意思的,分享一下开发过程和心得。
我是先做了这个网页再改成小程序。本次将web端版本开源。
这个工具主要是为了方便查询地图上的经纬度坐标,支持实时显示鼠标位置的坐标、点击固定坐标点,还能切换不同的地图和坐标格式,适合需要快速定位或者研究地图数据的朋友。
项目背景有时候我们需要精确地获取某个地点的经纬度,比如做地理信息相关的开发、户外活动规划,或者只是单纯好奇某个地方的坐标。市面上虽然有不少地图工具,但要么功能复杂,要么需要注册账号,或者界面不够直观。于是我就想着自己动手做一个简单易用的工具,核心需求是:
支持高德地图和OpenStreetMap切换
鼠标移动时实时显示坐标
点击地图可以固定坐标点
支持GCJ02、WGS84三种坐标系转换
界面简洁,适配手机和电脑
最终成品是一个纯前端的Web应用,部署在GitHub Pages上,打开浏览器就能用,体验还不错。
功能亮点这个工具虽然简单,但功能还算实用:
双地图支持:可以切换高德地图和OpenStreetMap。高德地图适合国内场景,OpenStree ...
简单的认识Cnamespace DataTypeApplication
{
class study
{
public int add(int a, int b)
{ int result;
result = a + b;
return result;
}
}
class Program
{
static void Main(string[] args)
{
study a = new study();
Console.WriteLine("Size of int: {0}",a.add(1,2));
Console.ReadLine();
}
}
}
1. 先看代码的整体结构这段代码可以分成两部分:
namespace DataTypeApplication(命名空间,类似“文件夹”)
class s ...
简单的认识Cnamespace DataTypeApplication
{
class study
{
public int add(int a, int b)
{ int result;
result = a + b;
return result;
}
}
class Program
{
static void Main(string[] args)
{
study a = new study();
Console.WriteLine("Size of int: {0}",a.add(1,2));
Console.ReadLine();
}
}
}
1. 先看代码的整体结构这段代码可以分成两部分:
namespace DataTypeApplication(命名空间,类似“文件夹”)
class s ...

rust
未读使用方法[source.crates-io]
replace-with = 'mirror'
[source.mirror]
registry = "https://mirrors.tuna.tsinghua.edu.cn/git/crates.io-index.git"
注:$CARGO_HOME:在 Windows 系统默认为:%USERPROFILE%\.cargo,在类 Unix 系统默认为:$HOME/.cargo。
注:cargo 仍会尝试读取不带 .toml 扩展名的配置文件(即 $CARGO_HOME/config),但从 1.39 版本起,cargo 引入了对 .toml 扩展名的支持,并将其设为首选格式。请根据使用的 cargo 版本选择适当的配置文件名。
在 Linux 环境可以使用下面的命令完成:
mkdir -vp ${CARGO_HOME:-$HOME/.cargo}
cat << EOF | tee -a ${CARGO_HOME:-$HOME/.cargo}/config.toml
[source.crates-io]
replace-w ...

在坐着车,突然想到了一个AI模型训练的一个好的idea。
心情本来不是特别坏,也不是特别好,但是想出这个idea之后,灵感就迸发了,很多事情都想通了。
立刻打开微信我的文件,一个人自言自语开始语音转文字。司机时不时眼睛微斜用余光看看我的精神状态是否正常。
现在我的主业是做ai的,曾经的遥感预处理都与我无关。
我是半路做AI的,不妨碍我现在能做出效果很好的应用。
我是真有这个信心,你说AI难吗?也很难,但是很多人都把ai集成为一个工具了,比如yolo,比如sovits
相对来说,模型我都是用开源的,哪个效果好我就用哪一个,我会更花更多的时间在后面的细节处理,在实战中检验效果。
对于初学AI者来说,我觉得更好的理解模型的方式是研究一个很基础模型,然后用笔和纸把模型的结构一层一层的从白纸上面写出来,理解它们这个层层递进的一个处理关系。
以前我写过拆解模型的过程。
【深度学习】从LeNet学神经网络搭建
LeNet很简单,很容易去解析,套路都是惊人的相似的。
再进阶一点,可以按照GPT训练的模式,自己构建一个小的模型。当然,此时学习的是训练的手法,怎么蒸馏等等。
我现在电脑算力不行,等我的5 ...

安卓手机都有加速度计,就是手机横置时让屏幕翻转的那种传感器,它可以侦测到手机的移动。
如果系统发现,同一个地理区域的手机突然同时震动,就说明地震了。谷歌就会向该区域的用户推送地震警报。
该系统于2021年4月,首先在新西兰和希腊上线,已覆盖98个国家/地区。2023年11月的菲律宾6.7级地震,2023年11月的尼泊尔5.7级地震,它都发送了警报。
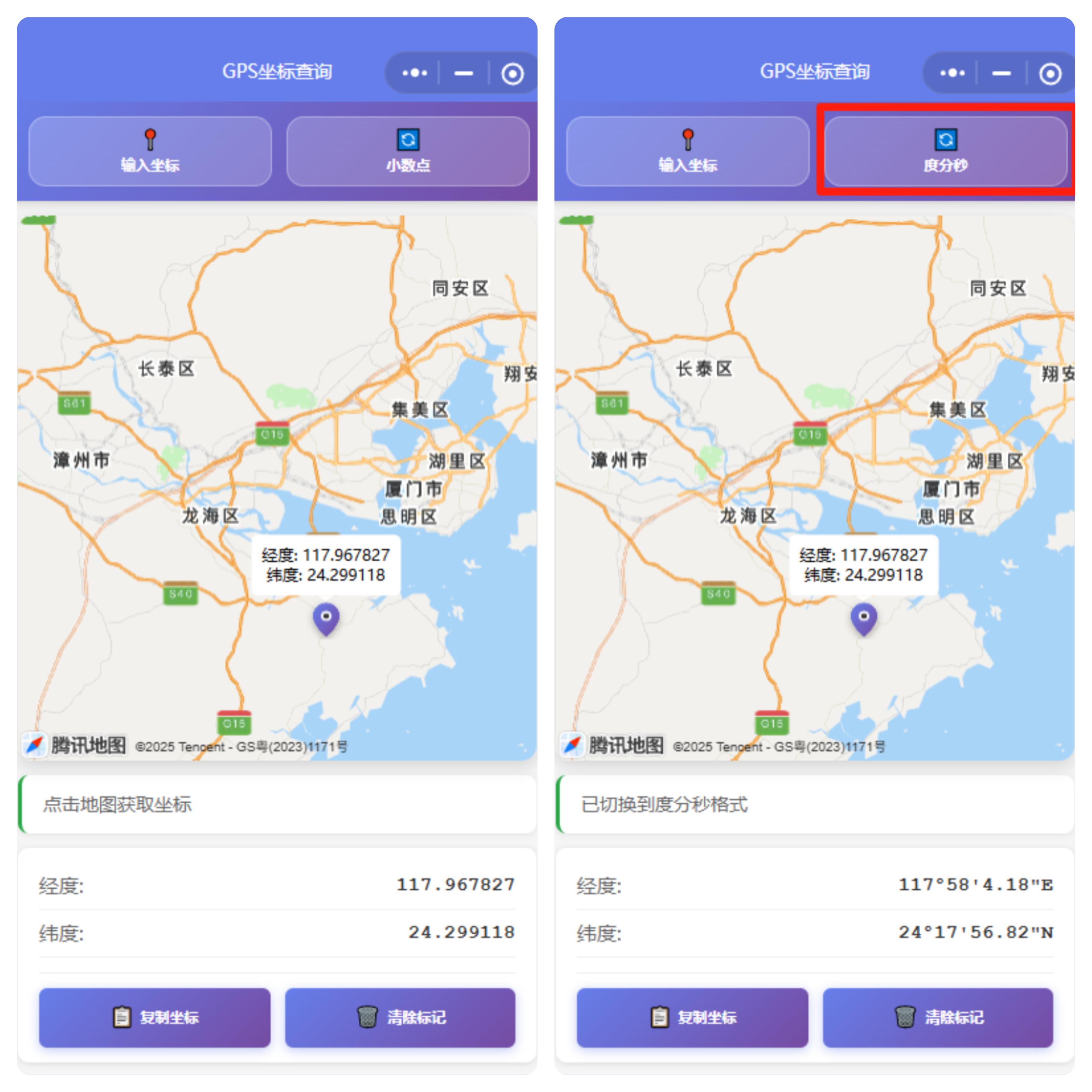
今天微信小程序 《小白gps工具》已通过审核,终于可以上线使用。
作为第一个版本,小白gps工具主要提供查询位置信息、输入坐标反查地图。
我没有条件外出进行gps静态测量,所以本次以google maps的经纬度为基准,在google maps、小白gps工具 手动刺点。进行简单的坐标精度测试。
挑选具有明显特征的位置:厦门旁边的双鱼岛,具体位置如下:
放大后显示如下:
再放大如下:
图上红色框的位置在google maps的经纬度是 118°4′0.26″E,24°23′7.37″N、
现在,在微信小程序 小白gps工具 测试该点的经纬度是118°4’0.17”E, 24°23’7.50”N如下:
纬度误差是13″,经度误差是9″,这种误差在日常简单的使用是没有问题的。
出现误差是因为二者的刺点是我手动操作的。
以上结果能验证 小白gps工具的位定是准确的。
当然,你想要更精确的gps定位信息,那么你需要去干测量外业。这点不在我们的讨论范围之内。
小白gps工具还提供 坐标反查,输入坐标gps信息,自动在地图上标记对应的地点。
坐标的格式有两种,小数点格式和 ...

