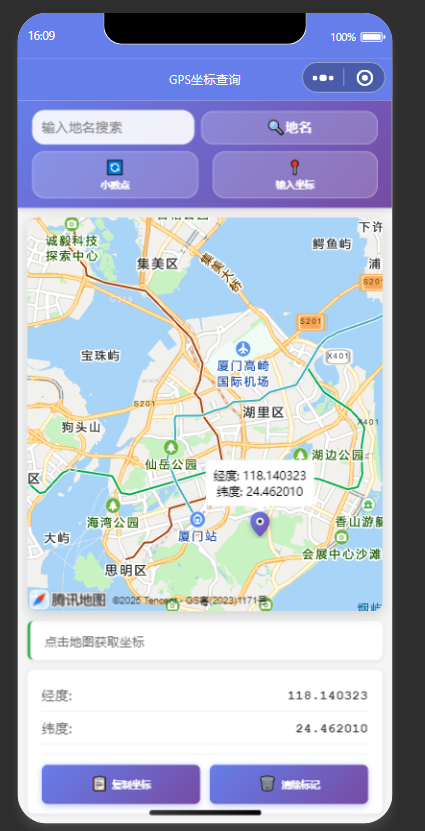
背景我开发了一款微信小程序,专注GPS坐标查询。功能包括地图点击获取经纬度、地名搜索定位、坐标格式转换(小数度/度分秒)、坐标分享及用户定位。
初期使用OpenStreetMap的Nominatim API进行地名搜索,但因国内访问不稳定,切换到高德地图地理编码API,提升了搜索效率。
实现要点1.地图交互使用微信小程序的 组件,支持点击获取GCJ02坐标,转换为WGS84显示,并添加标记点。
2.地名搜索通过高德地图API实现地名搜索,返回坐标,直接适配地图组件,响应快,覆盖广。
3.坐标格式转换支持小数度和度分秒格式,coord-convert.js 模块处理WGS84与GCJ02转换及格式切换。
/**
* 坐标转换工具类
* 移植自Python版本的coord_convert.py
*/
class CoordConverter {
constructor() {
this.x_pi = Math.PI * 3000.0 / 180.0;
this.a = 6378245.0; // 长半轴
this.ee = ...

你是否曾经有过这样的经历:用着好好的谷歌地图,一到国内,发现自己的GPS定位和地图上的道路总有那么一点点偏移?或者在使用卫星图时,发现道路、建筑的标注和实际影像对不上号?
别担心,你的手机没坏,地图App也没有出bug。你所遇到的,是一个涉及技术、法规和数据的有趣问题——地图坐标系。
今天,我们就来深入浅出地聊一聊这个话题。
一、 三大“标准”:谁在定义我们脚下的坐标?要理解各大地图App,我们首先要认识三个核心的坐标系“标准”:
WGS-84坐标系 (世界标准):这是我们最应该先认识的“老大哥”。它是由美国国防部制定的世界大地测量系统 (World Geodetic System 1984)。它的应用太广泛了,你手机里的GPS芯片接收卫星信号计算出的经纬度,就是基于这个标准。可以说,WGS-84是目前全球范围内的“事实标准”,代表着地球上一个点的“真实”坐标。
GCJ-02坐标系 (中国标准,又称“火星坐标系”):出于国家地理信息安全的考虑,中国国家测绘局规定,所有在中国境内发布和使用的地图产品,都必须采用一套国家加密的坐标系统。GCJ-02就是这套官方系统,它是在WGS-84的 ...
最近我会做两个微信小程序,代码初步写完。
第一个小程序正在备案,估计过两天备案审核通过后就上线,第二个小程序还没申请。
第一个小程序是查询经纬度。
第二个小程序是台风轨迹可视化。
在这两个小程序上线的时候,我会好好写一下这些小程序是怎么实现的、以及花了多少钱。
实际上,今年下半年,我计划开发一款GPS记录软件,用于完整记录用户的移动轨迹。我已经调研过市场上的类似应用,例如iOS平台上有一款名为“迷雾世界”的App。
然而,现有的这些App存在一个显著缺点:一旦开启,它们会实时从手机读取GPS信息,这会导致严重的电量消耗。
我的思维往往跳跃性很强,有时做事显得不太靠谱。但在许多情况下,我都能精准抓住事物的核心矛盾。
当然,发现问题远比解决问题容易得多。
如果能从根本上解决核心矛盾,许多衍生问题将迎刃而解。
等到明年年初,我会入手一张RTX 5090显卡,认真投入AI相关的自媒体创作。
目前,我已积累了一些AI自媒体的技术经验,但这个公众号专注于遥感领域,因此我不会在这里展开讨论。

2025年7月初,我写了一篇文章,讨论了在当前的AI时代,我们是否还需要学习编程。
我的答案是肯定的。我们不能只依赖AI。我们要看得懂AI给我们的答案,起码,我们要知道自己期待的答案是什么。
2025年7月第二篇《输出是最好的学习》,属于劝学。我本身是一个懒人,持续学习只是为了让自己生活过得好一点点。
在我们这个行业,如果要涉及到编程,你是绕不开GDAL,我们有必要认真学习GDAL。
那么学习rasterio还是gdal呢?我给出了一些建议。
当然,你学到好也不一定能找到工作,因为遥感领域最大的难题是本科生毕业找工作的问题。
同时,高校也在与时俱进,设立新专业:时空信息工程。
因许久未更新公众号,近日从过往积累的代码库中整理并提炼出 SAR 去噪相关内容,于 2025 年 7 月 31 日正式发布。
7月共发表了9篇公众号文章,大部分的业余时间是在当一个赛博监工。
结合ai编程,我做几个有意思的东西。比如你看到的开头的视频就是全自动生成的(输入文字,输出视频)。
我以前说过不想做视频的原因是我不想用自己的声音。现在完全可以使用克隆声音的技术。
7月的总结到此结束,祝大家都生活顺利。
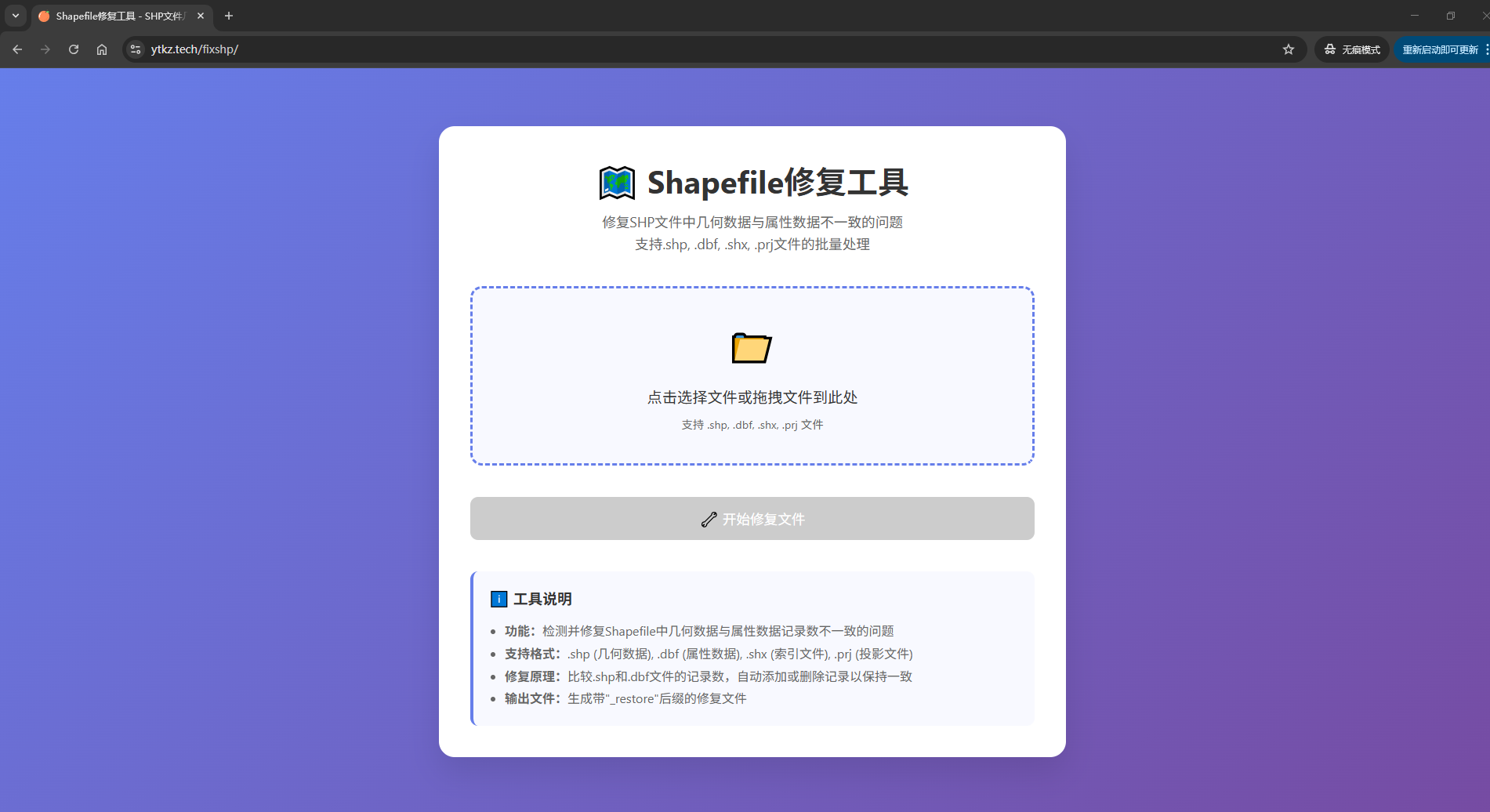
Shapefile修复工具 🗺️一个基于Web的Shapefile文件修复工具,专门用于检测和修复SHP文件中几何数据与属性数据不一致的问题。
这个项目展示了如何使用现代Web技术处理GIS数据格式,为GIS开发者和数据分析师提供了一个实用的在线工具。
📖 项目背景Shapefile是GIS领域最常用的矢量数据格式之一,由多个文件组成:
.shp - 存储几何数据
.dbf - 存储属性数据
.shx - 索引文件
.prj - 投影信息
在数据处理过程中,经常会出现几何数据与属性数据记录数不一致的问题,导致数据无法正常使用。
传统的解决方案需要使用专业的GIS软件或编写复杂的脚本,而这个工具提供了一个简单易用的Web界面来解决这个问题。
🌟 功能特点
🔍 智能检测:自动读取SHP和DBF文件头信息,精确计算记录数
🔧 自动修复:根据检测结果自动添加或删除记录以保持数据一致性
📁 多文件支持:支持.shp、.dbf、.shx、.prj文件的批量处理
🎨 现代化界面:响应式设计,支持拖拽上传,提供直观的用户体验
📊 实时反馈:详细的处理进度和结果展示,包 ...
rasterio是什么?GDAL (Geospatial Data Abstraction Library) 是地理空间数据处理领域的基石。它是一个用 C++ 编写的开源库
然而,GDAL 的强大也带来了它的“缺点”。它的官方 Python 绑定 (osgeo.gdal) 是从 C++ 代码自动生成的,这导致了它的 API 对于 Python 开发者来说不够友好。
Rasterio 的诞生就是为了解决 GDAL Python 绑定的这些痛点。它把自己定位为“GDAL for Python users”,它不是要取代 GDAL,而是架设在 GDAL 强大的能力之上,提供了一个更加现代、简洁和“Pythonic”的接口。
重要的一点是:Rasterio并没有重新发明轮子,它的核心功能依然依赖于GDAL。
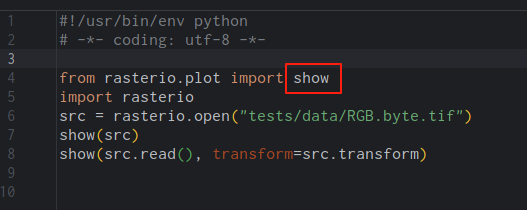
我以前是通过学习rasterio的源代码,进而学习行业内的高手是怎么封装GDAL完成不同的功能。
这个过程的步骤是:
1.安装pycharm
2.安装rasterio
3.打开在pycharm打开某个rasterio的代码。
比如下面的是rasterio封装了matplotlib、nump ...
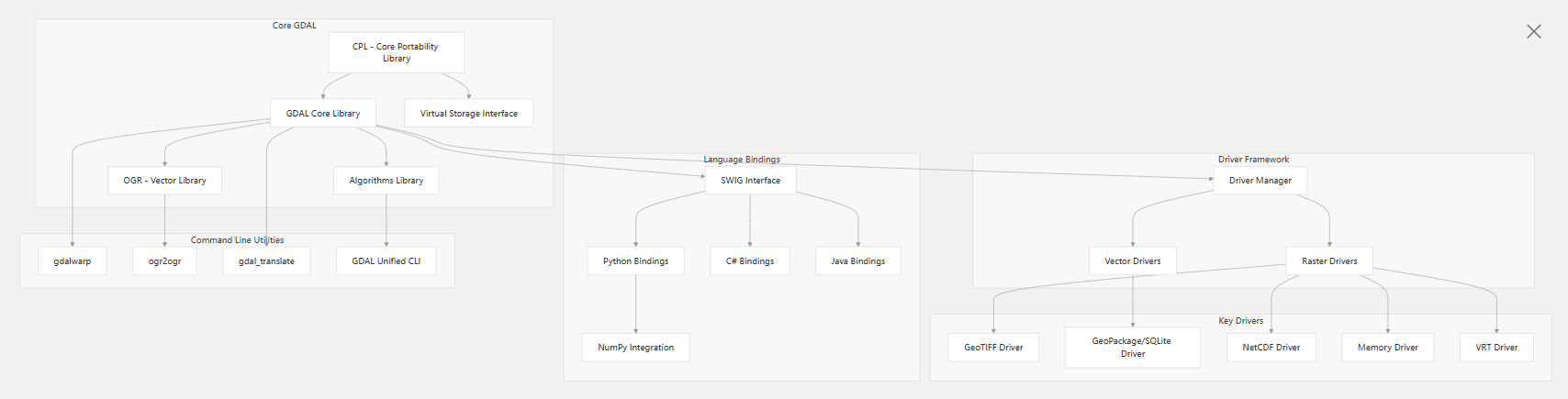
如果您是地理空间数据处理领域的一员,那么 GDAL/OGR 库想必是您工具箱中不可或缺的瑞士军刀。多年来,我们习惯了使用一系列独立的命令行工具,如 gdalinfo、gdal_translate、gdalwarp 和 ogr2ogr。它们功能强大,但数量繁多,有时我们不得不去翻阅文档,才能记起那个特定任务到底该用哪个命令。
现在,这一切都将成为历史。随着 GDAL 3.11 的发布,一个全新的、革命性的功能登场了——统一命令行界面(Unified CLI)。这不仅仅是一次小修小补,而是一次彻底的重构,旨在为您提供一个更一致、更直观、更强大的 GDAL 体验。
核心理念:从分散到统一过去,每个工具都是一个独立的程序。而现在,所有的功能都被整合到了一个单一的入口点之下:gdal。
新的语法结构清晰明了,采用了分层设计:
gdal [领域] [操作] [选项] [参数]
这里的“领域”通常指代您正在处理的数据类型,如 raster(栅格)、vector(矢量)或 mdim(多维数据)。“操作”则是您想要执行的具体任务,如 info(获取信息)、convert(转换格式)或 reproject ...
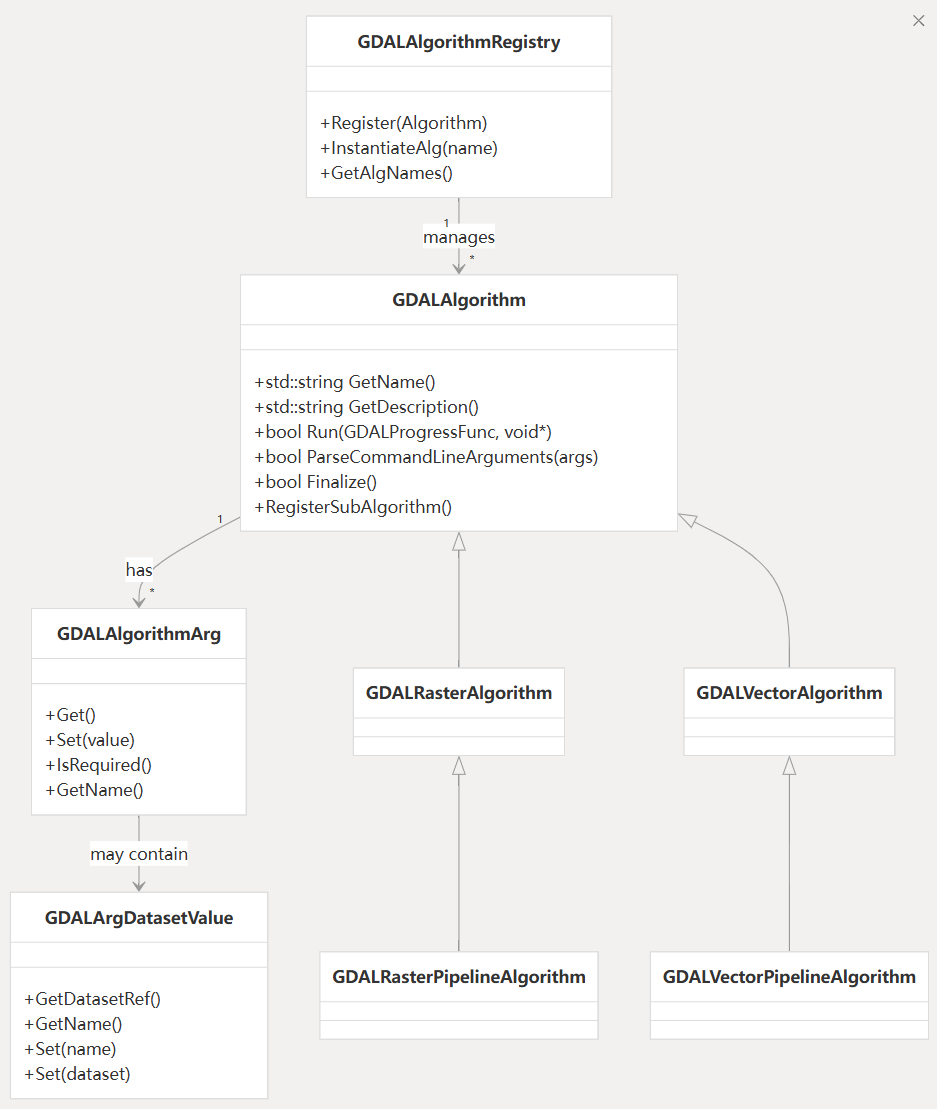
GDAL(地理空间数据抽象库,Geospatial Data Abstraction Library)是一个开源库,用于读取、写入和处理多种栅格和矢量地理空间数据格式。它为地理信息系统(GIS)提供了强大而统一的数据访问方式。。简要介绍 GDAL 的架构、关键组件和功能。
GDAL核心架构GDAL 由多个相互连接的子系统组成,它们协同工作,提供全面的地理空间数据处理功能。其核心架构包括栅格 (GDAL) 和矢量 (OGR) 处理组件,以及用于可移植性、算法和虚拟文件系统的支持库。
关键组件GDAL 的架构可分为以下几个核心部分:
核心库(Core GDAL Library)
提供统一的数据模型和 I/O 接口
使用 CPL(Core Portability Library)实现平台兼容性
包含虚拟文件系统(Virtual File Interface)
2. 矢量与栅格支持
OGR(矢量库):支持 GeoJSON、Shapefile、PostGIS 等矢量格式
栅格模块:支持 GeoTIFF、NetCDF、HDF5、JPEG2000 等格式
3. 驱动框架(Driver ...
GDAL_OGR简单的使用教程检测安装from osgeo import gdal
查看版本gdal.VersionInfo('VERSION_NUM')
# '2040100'
开启python异常默认情况下,发生错误时,GDAL/OGR Python绑定不会引发异常。相反,它们返回错误值(例如None),并将错误消息写入sys.stdout。你可以通过调用UseExceptions()函数来开启异常:
from osgeo import gdal
# 开启异常
gdal.UseExceptions()
# 打开不存在的数据集
ds = gdal.Open('test.tif')
# 开启异常前
ERROR 4: test.tif: No such file or directory
# 开启异常后
RuntimeError Traceback (most recent call last)
<ipython-input-5-6ef000fdc647> in <module>
----> ...
各位,今天我们来解构一下“遥感”这个专业。
一、遥感到底是个啥?核心定义: 遥感(Remote Sensing),顾名思义,即“遥远地感知”。它并非超能力,而是一门利用飞机、卫星等平台上的传感器,在不直接接触的情况下,获取地球及其他天体信息的科学与技术。
可以把它想象成给地球做一次全面的“健康体检”。我们使用的工具不是听诊器,而是各种传感器,它们能捕捉到肉眼看不见的光谱信息,比如:
可见光影像: 就是我们常见的“地球写真集”。
红外影像: 可以感知地表温度,监测火灾或农作物长势。
雷达影像: 能穿透云层,全天候无阻碍地“看”地表。
一言以蔽之,遥感的核心流程就两步:获取数据(拍片)和处理分析(修图解读)。
二、听着高大上,学遥感究竟有何用?学习遥感,你将解锁一个独特的视角——“上帝视角”。
当你的同学还在为一张地图上的等高线而苦恼时,你已经可以在电脑上拖动鼠标,以上帝的视角俯瞰山川湖海、城市变迁。这种体验,堪比在玩一款名为“地球Online”的即时战略游戏。
地理相关学科的魅力在于培养人的宏观思维和跨学科整合能力。遥感人,通过分析卫星影像,为国土规划、环境保护、灾害预警、国家安全 ...

